Опыт дизассемблирования большой .com программы
Содержание:
2.Как отличить данные от команд?
Любой дизассемблер путает данные и команды. Особенно это относится к .COM программам, где все перемешано. Рассмотрим простой пример:
pop cx ;03e56 ret ;03e57 ;----------------------------------------------------- add BYTE PTR ,al ;03e58 add BYTE PTR ,al ;03e5a m03e5c: mov BYTE PTR ds:d05830,01 ;03e5c
В этом фрагменте встретились две вычурных, повисших инструкции:
add BYTE PTR ,al ;03e58 add BYTE PTR ,al ;03e5a
Сверху они ограничены инструкцией возврата из подпрограммы ret, а снизу — меткой m03e5c. Ясно, что эти инструкции могут быть только данными. После переделки приведенный фрагмент должен выглядеть так:
pop cx ;03e56 ret ;03e57 ;----------------------------------------------------- d03e58 dw 0 ;03e58 d03e5a db 0 ;03e5a d03e5b db 0 m03e5c: mov BYTE PTR ds:d05830,01 ;03e5c
Тут возникает еще один вопрос: почему в одном случае стоит dw, а в другом — db? Ответ содержится в тексте, который выдал дизассемблер. Там можно найти такие инструкции:
mov si,WORD PTR ds:d03e58 ;03dd0 mov bl,BYTE PTR ds:d03e5a ;03dd4,
Откуда следует, что d03e58 рассматривается как слово, а d03e5a — как байт. Рассмотрим чуть более сложный, но, тем не менее, очень характерный пример.
b03f53: cmp al,05 ;03f53 jnz b03f6b ;03f55 ;Jump not equal(ZF=0) ..................................................... ret ;03f69 ;----------------------------------------------------- add BYTE PTR ,bh ;03f6a push es ;03f6c jnz b03f79 ;03f6d ;Jump not equal(ZF=0)
В приведенном фрагменте текста метка b03f6b отсутствует. Между тем эта метка должна «разрубить» пополам инструкцию add BYTE PTR ,bh , которая начинается в оригинальной программе, подвергаемой дизассемблированию, со смещения 03f6a. Выход здесь может быть только один — смещению 03f6a соответствует байт данных, а инструкция начинается со смещения 03f6b. Исправленный фрагмент должен выглядеть так:
b03f53: cmp al,05 ;03f53 jnz b03f6b ;03f55 ;Jump not equal(ZF=0) ...................................................... ret ;03f69 ;----------------------------------------------------- d03f6a db 0 ;03f6a b03f6b: cmp al,06h ;03f6b jnz b03f79 ;03f6d ;Jump not equal(ZF=0)
Путаница между данными и инструкциями возникает довольно часто. SOURSER способен выдавать целые метры бессмысленных инструкций. DisDoc 2.3 в этом отношении ведет себя лучше.
Установка
Рекомендуемым разработчиками способом установки и обновления Radare2 является установка из официального git-репозитория. Предварительно в системе должны присутствовать установленные пакеты git, build-essential и make.
Далее устанавливаем графическую оболочку для Radare2. Мы будет устанавливать официальный GUI под названием Iaito. Установим пакеты, необходимые для установки Iaito:
Для дистрибутивов Linux на базе Debian, есть готовые пакеты, ссылки на которые можно взять тут. Скачаем и установим нужную версию пакета:
Теперь установим плагин r2ghidra, который является интеграцией декомпилятора Ghidra для Radare2. Плагин не требует отдельной установки Ghidra, так как содержит в себе всё необходимое. Для установки плагин доступен в качестве r2pm пакета:
Установленный плагин автоматически интегрируется в GUI Iaito. После установки запускаем графическую оболочку и если все сделали правильно, то видим стартовый экран:

Теперь мы можем заняться нашим примером. Суть программы-примера заключается в следующем: при запуске на экране выводится некий токен, необходимый для того, чтобы зафиксировать выполнение задания и приватный SSH ключ. Но что-то пошло не так и в результате ключ выводится в некорректном виде, а токен не принимается в качестве правильного.
Открываем файл в Iaito, оставляем настройки анализа по умолчанию:
После того, как Radare2 проанализирует файл, смотрим результат, открывшийся во вкладке Dashboard:

Программа скомпилирована под 64-битную версию Linux, написана на языке C. Слева мы видим список функций, которые Radare2 смог обнаружить. Среди них импортируемые из библиотеки libc функции printf, puts и putchar, выводящие на экран строку по формату и символ.
Функция main – это главная функция программы. Выполнение начинается с неё. Кликнув два раза по её названию, открывается вкладка Disassembly с результатом её дизассемблирования:
Немного про Ассемблер
Ассемблер — машинно-ориентированный язык программирования низкого уровня. Представляет собой систему обозначений, используемую для представления в удобно читаемой форме программ, записанных в машинном коде. Назван по одноименной утилите, которая транслирует программу в машинный код процессора.
Команды ассемблера
Каждая команда Ассемблера — это команда для процессора. Синтаксис команды состоит из нескольких частей:
Команда — означает какую операцию необходимо выполнить. Например:
-
mov — команда пересылки данных. Копирует содержимое одного операнда в другой;
-
lea — вычисляет эффективный адрес операнда-источника и сохраняет его в регистре;
-
cmp — сравнение двух операндов;
-
условные и безусловные переходы (jmp, jne, je, jle, …) — безусловные и условные (требуется выполнение условия) переходы к меткам. Например, jump @exit выполняет безусловный переход к метке exit;
-
nop — однобайтовая команда, которая ничего не выполняет, а только занимает место и время. В основном используется для создание задержки в программе или как заполнитель удаленных инструкций. Например, команду проверки лицензионного ключа во взломанных программах заменяют на «ничего не делать»;
-
и тд
Операнды — то, над чем будут выполняться команды. Операндами могут быть названия регистров, ячейки памяти или служебные части команд.
Комментарий — понятно из названия, что это комментарий для удобства чтения кода. Пишется после точки с запятой.
Метки — обозначение участка кода. Также улучшает читаемость кода, но нужны еще и для перехода к помеченному им участку.
где:
-
mov — команда (перемещение значения из одного операнда в другой);
-
ax, — операнды (регистр и значение);
-
; <текст> — комментарий
Или рассмотрим другой пример как выглядит возведение числа в степень в Ассемблере:
Это же действие будет выглядеть на языке высокого уровня, например, Си как:
Decompilers[edit | edit source]
Akin to Disassembly, Decompilers take the process a step further and actually try to reproduce the code in a high level language. Frequently, this high level language is C, because C is simple and primitive enough to facilitate the decompilation process. Decompilation does have its drawbacks, because lots of data and readability constructs are lost during the original compilation process, and they cannot be reproduced. Since the science of decompilation is still young, and results are «good» but not «great», this page will limit itself to a listing of decompilers, and a general (but brief) discussion of the possibilities of decompilation.
Decompilation: Is It Possible?edit | edit source
In the face of optimizing compilers, it is not uncommon to be asked «Is decompilation even possible?» To some degree, it usually is. Make no mistake, however: an optimizing compiler results in the irretrievable loss of information. An example is in-lining, as explained above, where code called is combined with its surroundings, such that the places where the original subroutine is called cannot even be identified. An optimizer that reverses that process is comparable to an artificial intelligence program that recreates a poem in a different language. So perfectly operational decompilers are a long way off. At most, current Decompilers can be used as simply an aid for the reverse engineering process leaving lots of arduous work.
Common Decompilersedit | edit source
- Hex-Rays Decompiler
- Hex-Rays is a commercial decompiler. It is made as an extension to popular IDA-Pro disassembler. It is currently the only viable commercially available decompiler which produces usable results. It supports both x86 and ARM architecture.
- ILSpy
- ILSpy is an open source .NET assembly browser and decompiler.
- DCC
- RetDec
- The Retargetable Decompiler is a freeware web decompiler that takes in ELF/PE/COFF binaries in Intel x86, ARM, MIPS, PIC32, and PowerPC architectures and outputs C or Python-like code, plus flow charts and control flow graphs. It puts a running time limit on each decompilation. It produces nice results in most cases.
- Reko
- a modular open-source decompiler supporting both an interactive GUI and a command-line interface. Its pluggable design supports decompilation of a variety of executable formats and processor architectures (8- , 16- , 32- and 64-bit architectures as of 2015). It also supports running unpacking scripts before actual decompilation. It performs global data and type analyses of the binary and yields its results in a subset of C++.
- C4Decompiler
- C4Decompiler is an interactive, static decompiler under development (Alpha in 2013). It performs global analysis of the binary and presents the resulting C source in a Windows GUI. Context menus support navigation, properties, cross references, C/Asm mixed view and manipulation of the decompile context (function ABI).
- Boomerang Decompiler Project
- Boomerang Decompiler is an attempt to make a powerful, retargetable decompiler. So far, it only decompiles into C with moderate success.
- Reverse Engineering Compiler (REC)
- REC is a powerful «decompiler» that decompiles native assembly code into a C-like code representation. The code is half-way between assembly and C, but it is much more readable than the pure assembly is. Unfortunately the program appears to be rather unstable.
- ExeToC
- ExeToC decompiler is an interactive decompiler that boasted pretty good results in the past.
- snowman
- Snowman is an open source native code to C/C++ decompiler. Supports ARM, x86, and x86-64 architectures. Reads ELF, Mach-O, and PE file formats. Reconstructs functions, their names and arguments, local and global variables, expressions, integer, pointer and structural types, all types of control-flow structures, including switch. Has a nice graphical user interface with one-click navigation between the assembler code and the reconstructed program. Has a command-line interface for batch processing.
- Ghidra
- Ghidra is a reverse engineering package that includes a decompiler. It was written by the NSA for internal work, and apparently released because they didn’t want to have to re-train every new person they hired. It is written in Java.
Архитектуры RISC
MCS-51
MCS-51 (Intel 8051) — классическая архитектура микроконтроллера. Для неё существует кросс-ассемблер ASM51, выпущенный корпорацией MetaLink.
Кроме того, многие фирмы-разработчики программного обеспечения, такие, как IAR или Keil, представили свои варианты ассемблеров. В ряде случаев применение этих ассемблеров оказывается более эффективным благодаря удобному набору директив и наличию среды программирования, объединяющей в себе профессиональный ассемблер и язык программирования Си, отладчик и менеджер программных проектов.
AVR
На данный момент для AVR существуют 4 компилятора производства Atmel (AVRStudio 3, AVRStudio 4, AVRStudio 5 и AVRStudio 6, AVRStudio 7).
В рамках проекта AVR-GCC (он же WinAVR) существует компилятор avr-as (это портированный под AVR ассемблер GNU as из GCC).
Также существует свободный минималистический компилятор avra.
Платные компиляторы: IAR (EWAVR), CodeVisionAVR, Imagecraft. Данные компиляторы поддерживают языки Assembler и C, а IAR ещё и C++.
Существует компилятор с языка BASIC — BASCOM, также платный.
ARM
| Поставщик IDE | Компилятор | Поддерживаемые языки | Условия использования |
|---|---|---|---|
| Си/C++/Assembler | Shareware (не более 32kb) | ||
| Си/C++/Assembler | Commercial | ||
| Си/C++/Assembler. | |||
| Си/C++/Assembler |
PIC
Средой разработки, выпускаемой компанией Microchip Technology для создания, редактирования и отладки программ для микроконтроллеров семейства PIC, является MPLAB. Среда включает в себя трансляторы с языка ассемблер MPASM и ASM30 для различных семейств микроконтроллеров PIC. Современные версии среды «MPLAB X IDE» являются мультиплатформенными и работают под различными операционными системами для ЭВМ. Среда распространяется бесплатно.
Оговорочки
Хочу сразу оговориться, что правильно говорить не «ассемблер» (assembler), а «язык ассемблера» (assembly language), потому как ассемблер – это транслятор кода на языке ассемблера (т.е. по сути, программа MASM, TASM, fasm, NASM, UASM, GAS и пр., которая компилирует исходный текст на языке ассемблера в объектный или исполняемый файл). Тем не менее, из соображения краткости многие, говоря «ассемблер» (асм, asm), подразумевают именно «язык ассемблера».
Синтаксис директив, стандартных макросов и пр. структурных элементов различных диалектов (к примеру, MASM, fasm, NASM, GAS), могут отличаться довольно существенно. Мнемоники (имена) инструкций (команд) и регистров, а также синтаксис их написания для одного и того же процессора примерно одинаковы почти во всех диалектах (заметным исключением среди популярных ассемблеров является разве что GAS (GNU Assembler) в режиме синтаксиса AT&T для x86, где к именам инструкций могут добавляться суффиксы, обозначающие размер обрабатываемых ими данных, что бывает довольно удобно, но там есть и другие нюансы, сбивающие с толку программиста, привыкшего к классическому ассемблеру, к примеру, иной порядок указания операндов, хотя всё это лечится специальной директивой переключения в режим классического синтаксиса Intel).
Поскольку ассемблер – самый низкоуровневый язык программирования, довольно проблематично написать код, который корректно компилировался бы для разных архитектур процессоров (например, x86 и ARM), для разных режимов одного и того же процессора (16-битный реальный режим, 32-битный защищённый режим, 64-битный long mode; а ещё код может быть написан как с использованием различных технологий вроде SSE, AVX, FMA, BMI и AES-NI, так и без них) и для разных операционных систем (Windows, Linux, MS-DOS). Хоть иногда и можно встретить «универсальный» код (например, отдельные библиотеки), скажем, для 32- и 64-битного кода ОС Windows (или даже для Windows и Linux), но это бывает нечасто. Ведь каждая строка кода на ассемблере (не считая управляющих директив, макросов и тому подобного) – это отдельная инструкция, которая пишется для конкретного процессора и ОС, и сделать кроссплатформенный вариант можно только с помощью макросов и условных директив препроцессора, получая в итоге порой весьма нетривиальные конструкции, сложные для понимания.
ПОЧЕМУ DisDoc?
SOURSER — это название знают все, кто хотя бы краем уха слышал о дизассеблировании. Считается, что это дизассеблер замечательный, мощный, не имеющий конкурентов. Я думаю, что слухи об огромных преимуществах SOURSERа силь но преувеличены. У меня сложилось такое впечатление, что при дизассемблирова нии небольших программ (до 7 кб.) SOURSER предпочтительнее. Когда программа велика (в моем случае — 58 кб ), SOURSER работает очень медленно и, на мой взгляд, не дает никаких преимуществ.
Выбор дизассемблера DisDoc 2.3 был для меня во многом случаен. Начиная работу, я получил тексты на ассемблере как с помощью SOURSERa (версия 3.07), так и с помощью дизассемблера DisDoc 2.3. Затем оба текста после устранения очевидных ошибок были ассемблированы. И вот, то, что было выдано SOURSERом, повисло сразу, а то, что выдал DisDoc 2.3, прежде чем повиснуть, вывело на экран несколько линий. Это и определило выбор. В процессе работы я не раз имел возможность оценить основное преимущество дизассемблера DisDoc — интуитивно понятный, неизощренный, удобный и компактный листинг.
Чтобы понять дальнейшее, необходимо познакомиться с отрывком из листинга, который выдает DisDoc 2.3
mov cx,WORD PTR ds:d02453 ;02430 b02430: add cx,bx ;02434 mov bx,99e7h ;02436 mov dx,WORD PTR ds:d02449 ;02439 mov al,BYTE PTR ds:d02446 ;0243d call s383 ;<09060> ;02440 push cs ;02443 pop ds ;02444 ret ;02445 ;----------------------------------------------------- d02446 db 00 ;02446 . d02447 db 00,00 ;02447 .. d02449 db 00,00 ;02449 ..
В поле комментариев указано смещение, которое имела данная инструкция в исходной программе. Например, если вы в исходной программе, подвергаемой дизассемблированию, посмотрите отладчиком смещение 02434, то там окажется инструкция add cx,bx — на это можно положиться! Очень хороши названия меток и элементов данных. По ним сразу можно понять, какое смещение они имели в исходной программе. Например, метка b02430 имела смещение 02430, элемент данных d02446 имел смещение 02446 и т.д. То же самое относится и к подпрограммам. После вызова подпрограммы в треугольных скобках указано смещение, которое имела эта подпрограмма в исходной программе. Например, подпрограмма s383 начиналась в исходной программе со смещения 09060. Такая организация листинга позволяет сохранить однозначное соответствие с исходной программой, что дает возможность проверить отладчиком сомнительные куски кода и данных, сравнить текст, выданный дизассемблером с тем, что есть на самом деле. Это поистине драгоценная возможность. Нужно сказать, что DisDoc имеет большие недостатки, о которых речь еще пойдет, и, следовательно, применение того или иного дизассемблера — дело вкуса.
В любом случае обязательно встретятся
Как мыслит процессор
Чтобы понять, как работает Ассемблер и почему он работает именно так, нам нужно немного разобраться с внутренним устройством процессора.
Кроме того, что процессор умеет выполнять математические операции, ему нужно где-то хранить промежуточные данные и служебную информацию. Для этого в самом процессоре есть специальные ячейки памяти — их называют регистрами.
Регистры бывают разного вида и назначения: одни служат, чтобы хранить информацию; другие сообщают о состоянии процессора; третьи используются как навигаторы, чтобы процессор знал, куда идти дальше, и так далее. Подробнее — в расхлопе ↓
Какими бывают регистры
Общего назначения. Это 8 регистров, каждый из которых может хранить всего 4 байта информации. Такой регистр можно разделить на 2 или 4 части и работать с ними как с отдельными ячейками.
Указатель команд. В этом регистре хранится только адрес следующей команды, которую должен выполнить процессор. Вручную его изменить нельзя, но можно на него повлиять различными командами переходов и процедур.
Регистр флагов. Флаг — какое-то свойство процессора. Например, если установлен флаг переполнения, значит процессор получил в итоге такое число, которое не помещается в нужную ячейку памяти. Он туда кладёт то, что помещается, и ставит в этот флаг цифру 1. Она — сигнал программисту, что что-то пошло не так.
Флагов в процессоре много, какие-то можно менять вручную, и они будут влиять на вычисления, а какие-то можно просто смотреть и делать выводы. Флаги — как сигнальные лампы на панели приборов в самолёте. Они что-то означают, но только самолёт и пилот знают, что именно.
Сегментные регистры. Нужны были для того, чтобы работать с оперативной памятью и получать доступ к любой ячейке. Сейчас такие регистры имеют по 32 бита, и этого достаточно, чтобы получить 4 гигабайта оперативки. Для программы на Ассемблере этого обычно хватает.
Так вот: всё, с чем работает Ассемблер, — это команды процессора, переменные и регистры.
Здесь нет привычных типов данных — у нас есть только байты памяти, в которых можно хранить что угодно. Даже если вы поместите в ячейку какой-то символ, а потом захотите работать с ним как с числом — у вас получится. А вместо привычных циклов можно просто прыгнуть в нужное место кода.
Инcтрукция if
Данную инструкцию довольно просто отличить в дизассемблированном виде от других инструкций. Её отличительное свойство — одиночные инструкции условного перехода je, jne и другие команды jump.
 1605790962062.png
1605790962062.png 1605790989407.png
1605790989407.png
Напишем небольшую программу на языке Си и дизассемблируем её с помощью radare2. Разницы между IDA PRO и radare2 при дизассемблировании этих программ не было обнаружено, поэтому я воспользуюсь radare2. Вы можете использовать IDA PRO.
Компилируем при помощи gcc. Команда . -m32 означает, что компилироваться код будет под архитектуру x86.
Чтобы посмотреть на код в radare2, напишем команду . Далее прописываем для анализа кода и переходим к функции main . Посмотрим на код с помощью команды .
 1605792900362.png
1605792900362.png
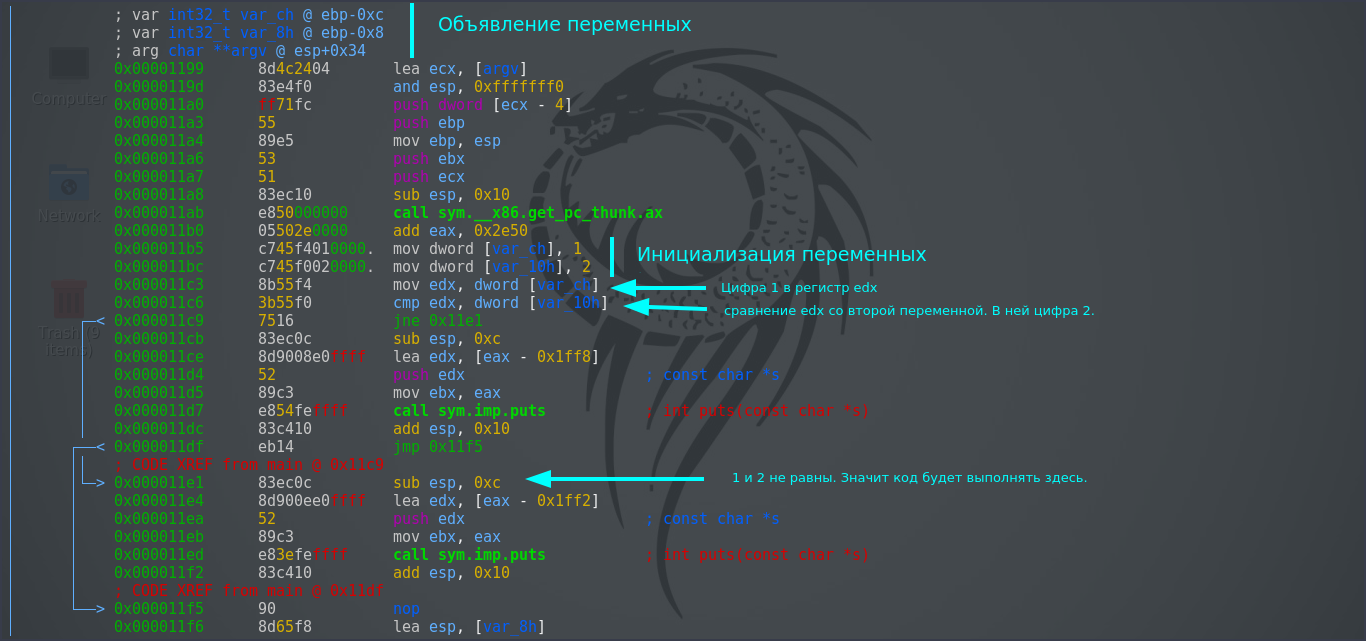
Первым делом в программе происходит объявление переменных ( int x; int y ), а затем значение 1 перемещается в var_ch (это переменная x) и значение 2 в var10h (это переменная y). Далее идёт сравнение (cmp) 1 и 2 (). Эти значения не равны. Значит jne ( jump if not equal) перейдёт по адресу 0x000011e1. Проще всего инструкцию if запомнить и определить в режиме графов (команда для для radare2 или клавиша пробел для IDA).
 1605792914861.png
1605792914861.png
Немного усложним задачу. Добавим вложенные инструкции. Попробуйте проанализировать этот код.
Начальное исследование прошивки
Кратко: на этом этапе выполняется предварительный анализ прошивки. Просмотр строк. Загрузка прошивки в IDA Pro.strings
а вы их увидели?STM32F042x4 STM32F042x6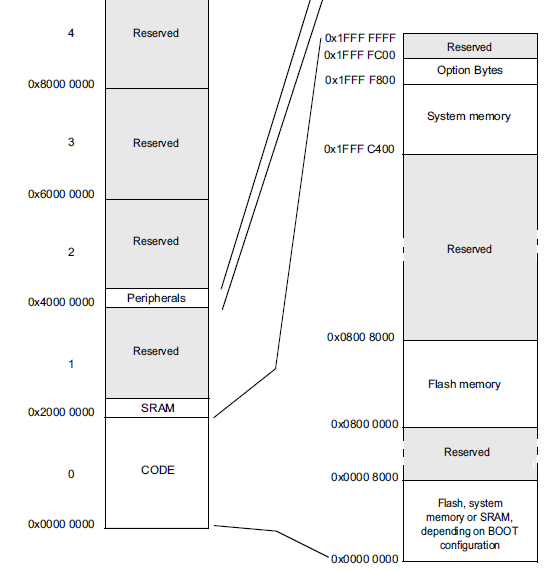 Processor TypeARM Little endianManual load
Processor TypeARM Little endianManual load Do you want to change the processor type0x08000000 – 0x08008000Loading address = 0x08000000
Do you want to change the processor type0x08000000 – 0x08008000Loading address = 0x08000000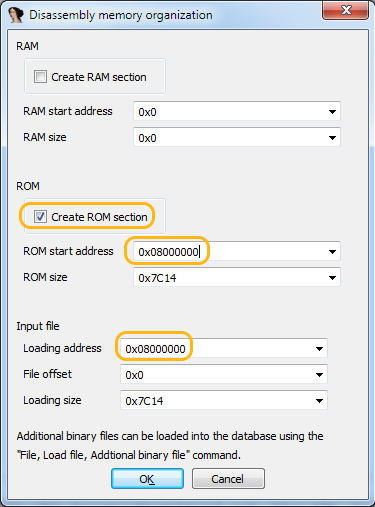 ARM and Thumb mode switching instructionsокно строк
ARM and Thumb mode switching instructionsокно строк
Примечание для начинающих
Любая программа/прошивка представляет собой набор двоичных данных. IDA Pro может по-разному интерпретировать эти данные исходного файла (представлять данные в виде команд или данных в том или ином формате). При этом тут нет кнопки «Назад» (Ctrl+Z), чтобы отменить выбранное отображение — нужно знать, как переключаться между разными режимами отображения. (Шпаргалка по горячим клавишам IDA Pro)
Реверс-инженер из кажущегося хаоса двоичных данных восстанавливает логику, структуру и читаемость.
Строки – важная информация при реверсе! Так как, по сути, среди всего набора двоичных данных являются наиболее просто и быстро воспринимаются человеком. Строки позволяют делать выводы о назначении функций, переменных и блоков кода.
Именуй просмотренные функции! По умолчанию, IDA даёт функциям имена по их стартовым адресам. При анализе держать в голове эти адреса весьма сложно, гораздо проще пользоваться осмысленными именами
Для того, чтобы поименовать функцию достаточно хотя бы её беглого анализа – это уже будет важным подспорьем для дальнейшего анализа.
Именуй распознанные переменные! Для того чтобы эффективнее проводить анализ блоков кода и функций, имеет смысл именовать переменные, которые распознала IDA, в соответствии с их назначением (всё, как в лучших практиках программирования).
Оставляй комментарии, чтобы не забыть важное. По аналогии с программированием, комментарии при реверсе позволяют дополнительно пояснять логику работы программы или отдельных её участков.
По возможности создавай структуры! IDA в своём арсенале имеет средство работы со структурами, имеет смысл освоить это средство и применять его при необходимости
При наличии структур исследуемый код станет еще проще для восприятия.
Идеология дизассемблирования
Как известно, машинный процесс ассемблирования — это процесс с потерями. Вне программы остается вся смысловая информация, например, комментарии. Обратный процесс машинного дизассемблирования эти потери естественно восстановить не может. Это может только человек. Поэтому разделение труда неизбежно. Отсюда вытекает и первая задача. В программе дизассемблера должно быть предусмотрено два режима — автоматический и интерактивный.
В SOURSERe основное внимание было уделено первой функции — автоматичности. Однако эффективность машинной работы была низка
Да и откуда она могла взяться при примитивном линейном алгоритме — сплошняком декодируй все байты файла, а потом гадай, где реальные коды, а где ложные. Даже человеку не просто решить эту задачу. И он то, чаще всего, применяет метод «научного тыка», по наитию. А как машину научить этому наитию?
В IDA PRO внимание уже уделили второй функции — интерактивности. И наработали мощный ресурс для ручной работы
Однако примитивный алгоритм машинной работы остался в общем прежним. И потому немалая часть этого ресурса направлена на компенсацию неэффективной машинной работы.
Все программы состоят из двух частей — области кода и области данных. И задача дизассемблирования прежде всего разобраться — что и где. Нагружать человека этой работой неразумно. Слишком уж она рутинна и объемна. Поэтому разделение труда должно быть не только количественное, а, прежде всего, качественное. Ясно, что человек умнее любой машины. Поэтому и заниматься он должен самой умной работой, оставив машине всю примитивную и рутинную. Иначе говоря, машина должна выявлять машинную функцию байтов кода, а человек ее смысловую функцию.
Главной частью программы, конечно, является код, а область данных, как приложение к нему и потому как бы вторична. Именно это представление сыграло злую шутку с разработчиками дизассемблеров. Они свое представление передали и дизассемблеру в виде обобщенного принципа. Вся дизассемблируемая программа является ОБЛАСТЬЮ КОДА, и задача машины в автоматическом режиме выявить области данных. А для того чтобы машина решила задачу в этом режиме четко и однозначно, ей должны быть даны также четкие и однозначные инструкции. А их увы, просто не существует при той идеологии. Потому мир дизассемблирования и топчется на месте.
Дизассемблер программы FE23
Работа над проектом FE23 была начата в октябре 2007 года.
По состоянию на апрель 2010 года в программе FE23 еще не
сделано многое из того, что было задумано. Однако, программа
уже давно дошла до такого уровня, когда ее пора показывать —
«выпускать в свет».
Несмотря на многие оставшиеся недоделки.
Основная «недоделка» в том, что дизассемблер «знает» еще
не все команды процессора. В таблицы дизасма внесены еще не
все команды даже из набора i386. Новые команды добавлялись
в таблицы по мере того, как эти команды требовались для
исследования конкретных файлов. В таблицах пока нет
привилегированных команд, поскольку соответствующие программы
пока ни разу не исследовались.
И нет команд сопроцессора (работа с плавающей запятой).
А тажке не попали пока в таблицы редко используемые команды.
Если при первом проходе дизасма встретится такая команда,
которая еще не включена в таблицы, то дизассемблер фиксирует
ошибку и считает, что луч в этом месте закончился. В протоколе
печатается сообщение об ошибке.
Критерием пригодности дизассемблера для исследования данного
конкретного файла может служить такая проверка — удается ли или нет
выполнить полностью (пройти до конца) первый проход дизасма.
Examples
The following command causes the metadata and disassembled code for the PE file to display in the Ildasm.exe default GUI.
The following command disassembles the file and stores the resulting IL Assembler text in the file MyFile.il.
The following command disassembles the file and displays the resulting IL Assembler text to the console window.
If the file contains embedded managed and unmanaged resources, the following command produces four files: MyApp.il, MyApp.res, Icons.resources, and Message.resources:
The following command disassembles the method within the class in and displays the output to the console window.
In the previous example, there could be several methods named with different signatures. The following command disassembles the instance method with the return type of void and the parameter types int32 and string.
Note
In the .NET Framework versions 1.0 and 1.1, the left parenthesis that follows the method name must be balanced by a right parenthesis after the signature: . Starting with the .NET Framework 2.0 the closing parenthesis must be omitted: .
To retrieve a method ( method in Visual Basic), omit the keyword . Class types that are not primitive types like and must include the namespace and must be preceded by the keyword . External types must be preceded by the library name in square brackets. The following command disassembles a static method named that has one parameter of type AppDomain and has a return type of AppDomain.
A nested type must be preceded by its containing class, delimited by a forward slash. For example, if the class contains a nested class named , the nested class is identified as follows: .
Примеры дизассемблеров
Дизассемблер может быть автономным или интерактивным. Автономный дизассемблер при запуске генерирует файл на ассемблере, который можно исследовать; интерактивный показывает эффект любого изменения, которое пользователь делает немедленно. Например, дизассемблер может изначально не знать, что часть программы на самом деле является кодом, и рассматривать его как данные; если пользователь указывает, что это код, получившийся дизассемблированный код отображается немедленно, что позволяет пользователю изучить его и предпринять дальнейшие действия во время того же запуска.
Любой интерактивный отладчик будет включать некоторый способ просмотра дизассемблера отлаживаемой программы. Часто один и тот же инструмент дизассемблирования будет упакован как автономный дизассемблер, распространяемый вместе с отладчиком. Например, objdump, часть GNU Binutils, относится к интерактивному отладчику GDB.
- Бинарный ниндзя
- ОТЛАЖИВАТЬ
- Интерактивный дизассемблер (ИДА)
- Гидра
- Hiew
- Дизассемблер бункера
- Netwide Disassembler (Ndisasm), спутник Сетевой ассемблер (НАСМ).
- ОЛИВЕР (CICS интерактивный тест / отладка) включает дизассемблеры для Ассемблера, КОБОЛ, и PL / 1
- OllyDbg это 32-битный отладчик, анализирующий уровень ассемблера
- Radare2
- SIMON (пакетное интерактивное тестирование / отладка) включает дизассемблеры для Assembler, COBOL и PL / 1.
- Sourcer, комментирующий 16-битный / 32-битный дизассемблер для ДОС, OS / 2 и Windows к V Связь в 1990-е годы