Что такое веб-архив и как им пользоваться
Содержание:
- Восстановление сайта с помощью «Archivarix»
- Как посмотреть удаленную страницу в веб-архиве
- Как использовать веб-архив?
- web.archive.org
- Проекты, предоставляющие историю сайта
- Как проверять полученные статьи на уникальность
- Примечания[ | ]
- Особенности и преимущества сервиса
- Best Internet Wayback Machine Alternative
- Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
- Использование сервиса WebArchive
- r-tools.org
- Качаем сайт с web.archive.org
- Donation Process
- Индексация веб-страниц в интернете
- Как скачать все изменения страницы из веб-архива
- Примечания
Восстановление сайта с помощью «Archivarix»
После выбора наиболее приемлемого тарифного плана можно приступить к самому главному, именно — восстановлению некогда преданного забвению веб-ресурса.
Кроме того, «Архиварикс» может скачивать и восстанавливать не только сайт из Веб Архива, но и тех. которые на момент скачивания являются рабочими — находятся в режиме онлайн, именно это и есть ключевое отличие данного сервиса от всевозможных «парсеров», а также различного рода «качалок».
Главная задача «Архиварикса» состоит в восстановлении полностью функциональной и работоспособной версии сайта, дабы тот мог полноценно использоваться на сервере пользователя.
Archivarix
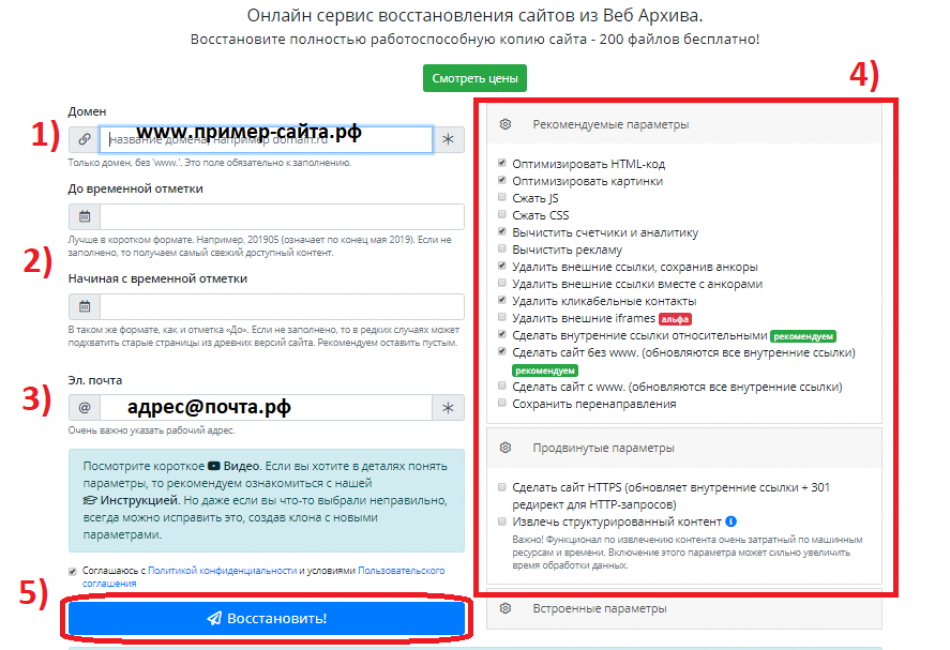
Приступим к обзору первого модуля, отвечающего за восстановление сайта из Архива. Чтобы воспользоваться им, необходимо перейти по адресу: https://ru.archivarix.com/
Далее необходимо заполнить все пункты, находящиеся на странице.
А именно:
- Вспомнить и ввести корректное название доменного имени, например: «пример-сайта.рф».
- Выбрать актуальную версию сайта, указав необходимую дату «до определенной временной отметки» или наоборот, «начиная с определенной временной отметки». Если оставить данный пункт незаполненным, то пользователь получить наиболее актуальную версию веб-сайта.
- В третьей строке необходимо указать действующий и рабочий адрес электронной почты, на который впоследствии придет важная информация — уведомление и ссылка на скачивание архива.
- Для продвинутых пользователей была предусмотрены опции «Рекомендуемые/Продвинутые/Встроенные параметры», благодаря которым можно произвести тонкую настройку различных параметров.
- Нажимаем клавишу «Восстановить», разобравшись предварительно со всеми предыдущими пунктами и параметрами.
После этого система займется сбором и упорядочиванием всей необходимой информации и компонентов сайта, после этого «Архиварикс» сформирует письмо, в котором будет детально указан результат анализа полученных данных: размер сайта, количество файлов, типы данных в фактическом и процентном соотношении.
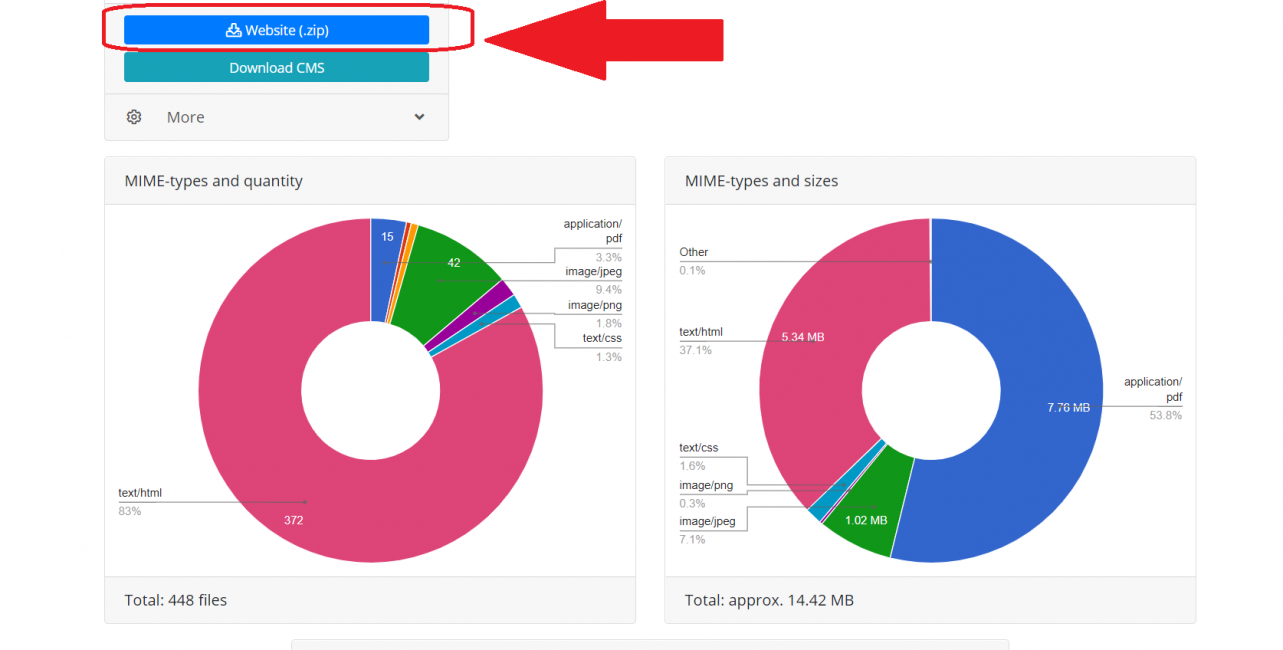
Информация о сайте, собранная Архивариксом
Чтобы скачать восстановленную копию сайта в zip-архиве — необходимо нажать на кнопку «Website (.zip)», расположенную в верхнем левом углу (как показано на скриншоте выше).
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.

Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.

Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
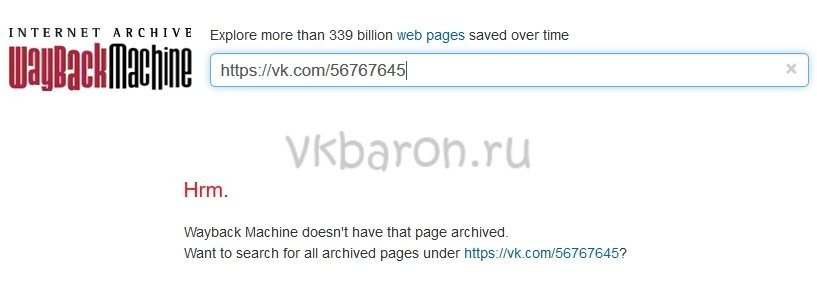
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
- archive.is;
- webcitation.org;
- freezepage.com;
- perma.cc.
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Как использовать веб-архив?
 Форма для поиска информации на Peeep.us
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
web.archive.org


В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
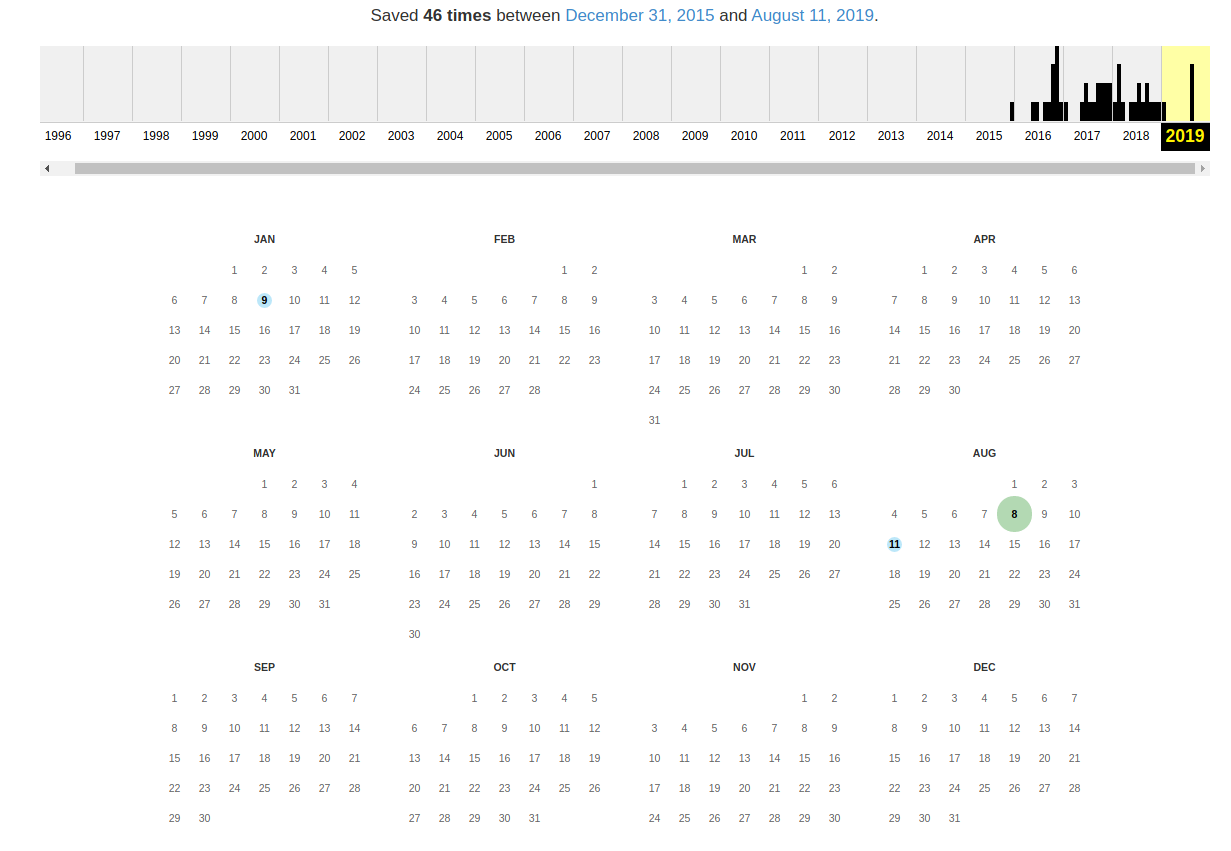
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.


Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
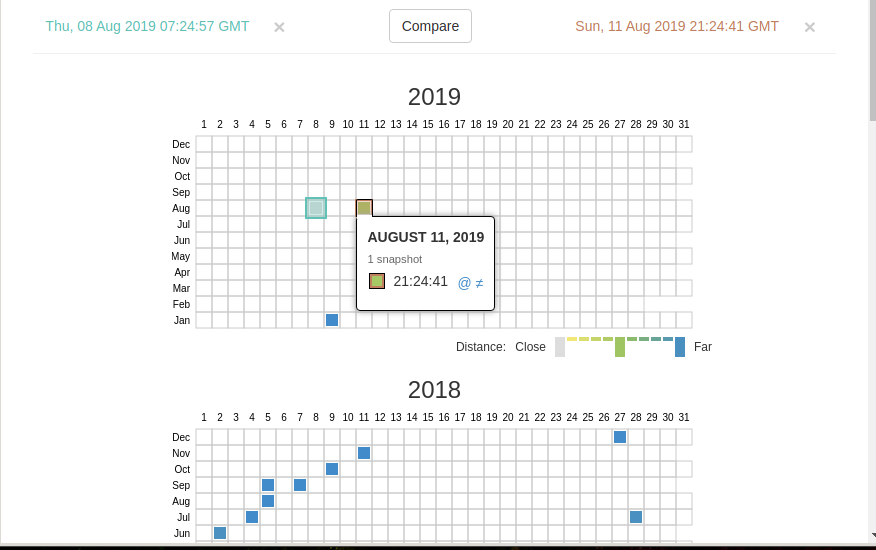
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
Проекты, предоставляющие историю сайта
Peeep.us в действии
Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.
Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».
Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
Примечания[ | ]
- Internet Archive: Bios (англ.) — Internet Archive .
- Глобальный рейтинг сайта archive.org (англ.). Alexa Internet. Дата обращения 20 июня 2020.
- https://projects.propublica.org/nonprofits/organizations/943242767
- 10,000,000,000,000,000 bytes archived! (неопр.) . Архивировано 28 ноября 2012 года.
- Defining Web pages, Web sites and Web captures (неопр.) .
- Donate to the Internet Archive! (англ.). archive.org. Дата обращения 28 марта 2020.
- Internet Archive officially a library (неопр.) .Internet Archive (7 мая 2007). Дата обращения 31 августа 2020.
- Internet Archive: In the Collections (неопр.) (недоступная ссылка).Wayback Machine (6 июня 2000). Дата обращения 1 сентября 2020. Архивировано 6 июня 2000 года.
- Bowman, Lisa M . Net archive silences Scientology critic, CNET News.com (24 сентября 2002). Архивировано 16 июля 2012 года. Дата обращения 4 января 2007.
- Jeff. exclusions from the Wayback Machine(неопр.) (Blog).Wayback Machine Forum . Internet Archive (23 сентября 2002). Дата обращения 4 января 2007. Архивировано 25 августа 2011 года.Author and Date indicate initiation of forum thread
- Miller, Ernest Sherman, Set the Wayback Machine for Scientology(неопр.) (Blog).LawMeme . Yale Law School (24 сентября). Дата обращения 4 января 2007. Архивировано 25 августа 2011 года.The posting is billed as a ‘feature’ and lacks an associated year designation; comments by other contributors appear after the ‘feature’
- Maximillian Dornseif. Government mandated blocking of foreign Web content (англ.).preprint cs/0404005 16. arXiv (2004). Дата обращения 26 ноября 2020.
- Bulk Access to OCR for 1 Million Books, via Open Library Blog, by raj, 24 ноября 2008. (неопр.) . Архивировано 28 ноября 2012 года.
- Free Software Awards Announced (неопр.) . Архивировано 28 ноября 2012 года.
- Стали известны номинанты ежегодной награды Free Software Awards (неопр.) (недоступная ссылка). Дата обращения 17 сентября 2020. Архивировано 18 июля 2011 года.
- Производится блокировка экстремистского видео террористической организации «Исламское государство Ирака и Леванта» в сети Интернет (неопр.) . Роскомнадзор (24 октября 2014).
- Роскомнадзор внёс «архив интернета» в реестр запрещённых сайтов // Meduza. — 2014. — 25 октября.
- ↑ 12 Роскомнадзор заблокировал архив интернета // РБК. 25 июня 2015 года.
- Роскомнадзор заблокировал страницу «архива интернета» за экстремизм // Lenta.ru. 25 июня 2020 года.
- Роскомнадзор заблокировал архив интернета из-за «Одиночного джихада» // Московский комсомолец. 25 июня 2020 года.
- АЗАПИ хочет навечно заблокировать «Архив интернета» // РосКомСвобода. — 2014. — 22 августа.
- Xenia Voronina . Experts explain reason for websites blocking in Kazakhstan (англ.), Республиканская газета «Казахстанская правда» (21 October 2015). Дата обращения 26 ноября 2020.
- Kyrgyzstan Blocks Archive.org on ‘Extremism’ Grounds (англ.), Global Voices advox (21 July 2017). Дата обращения 26 ноября 2017.
- ‘Bollywood blocks the Internet Archive’ — BBC News
- Access to Internet Archive’s Wayback Machine Blocked in India
- Statement and Questions Regarding an Indian Court’s Order to Block archive.org | Internet Archive Blogs
- Update: Internet Archive contacted Indian govt regarding the block, but got no response — MediaNama
Особенности и преимущества сервиса
«Archivarix» работает напрямую с API «Веб Архива» и это — его принципиальное преимущество
В отличие от скачивания напрямую (когда скрипт просто переходит по ссылкам, имеющимся в Архиве и копирует информацию о сайте), взаимодействие с API позволяет сервису моментально обнаружить и оценить данные (их количество и целостность), что очень важно, поскольку web.archive.org нередко меняет свои алгоритмы и работает нестабильно
Кроме того, он (архив) не всегда предоставляет прямые и/или корректные ссылки, тогда как взаимодействие а АПИ — позволяет восстановить все имеющиеся компоненты сайта.
Завершив анализ и загрузку, «Архиварикс» передает данные в модуль обработки, который формирует сайт, пригодный для инсталляции на Ngix или Apache. Сервис осуществляет удаление рекламы, аналитики и счетчиков с восстановленных веб-сайтов посредством сложной и длительной проверки данных по базам рекламных провайдеров, а также сборщиков аналитики.
«Archivarix» имеет собственную CMS, которая в значительной мере облегчает восстановление и редактирование сайтов.
Как перенести контент из «Веб Архива» на WordPress?
Наличие параметра «Извлечение структурированного контента» позволит сделать WordPress блог как из восстановленного, так и из любого другого сайта.
Для этого необходимо:
1
Перейти в раздел «Восстановить сайт».
2
Выбрать опцию «Извлечь структурированный контент».
Извлечь структурированный контент
3
Нажимаем клавишу «Восстановить».
4
После окончания процесса восстановления, сервис переносит его на собственный сервер и начинает извлечение различного контента, исключая дубли, элементы управления и прочий ненужный материал. После этого на электронный адрес придет емейл с подтверждением, где выбираем пункт «Статьи» (Articles (.zip))».
«Статьи» (Articles (.zip))»
5
Заходим в админ панель WordPress и выбираем: «Инструменты -> Импорт -> WordPress -> Запустить импорт» и выбираем файл с расширением «.wxr», который находится в скачанном zip-архиве.
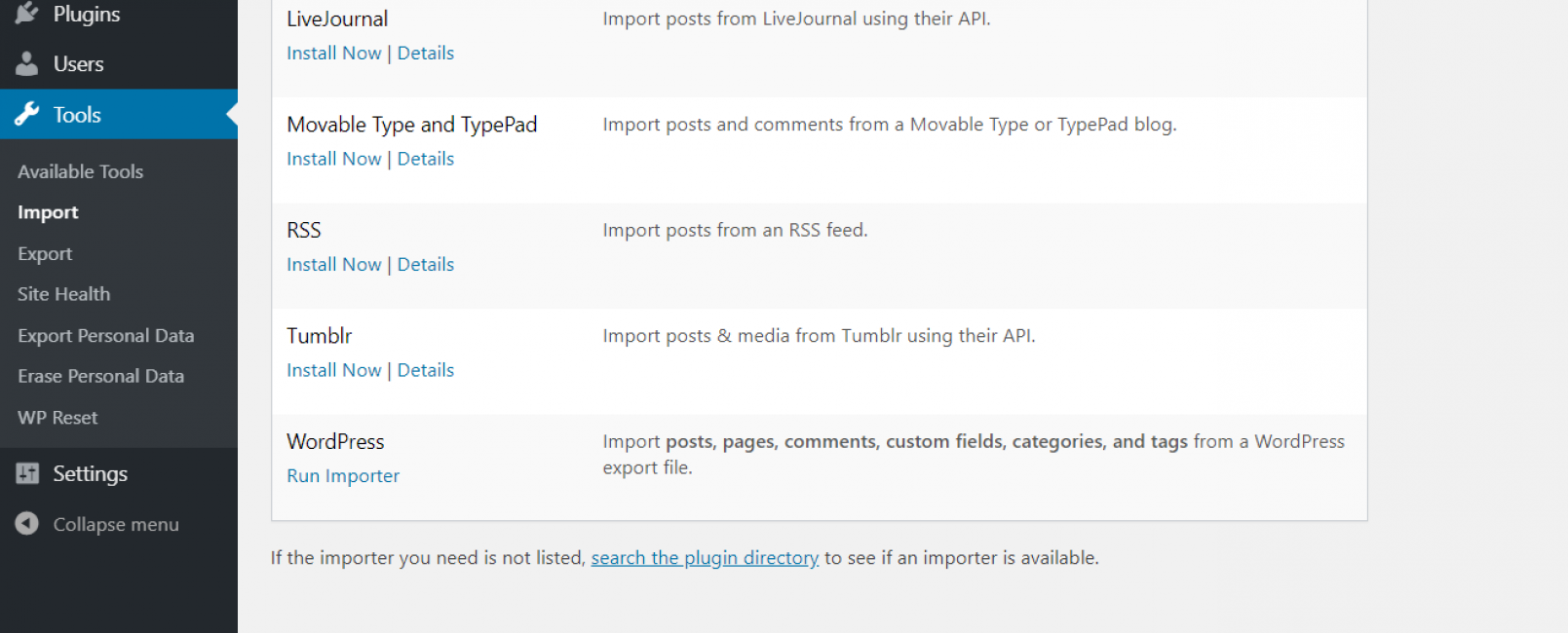
Импортируем данные
6
Если на сайте имеет большое количество изображений, то следует воспользоваться плагином для WordPress под названием Archivarix External Images Importer. Устанавливаем его и во вкладке плагина выбираем Download settings, меняем параметр Start downloading на Immediately.
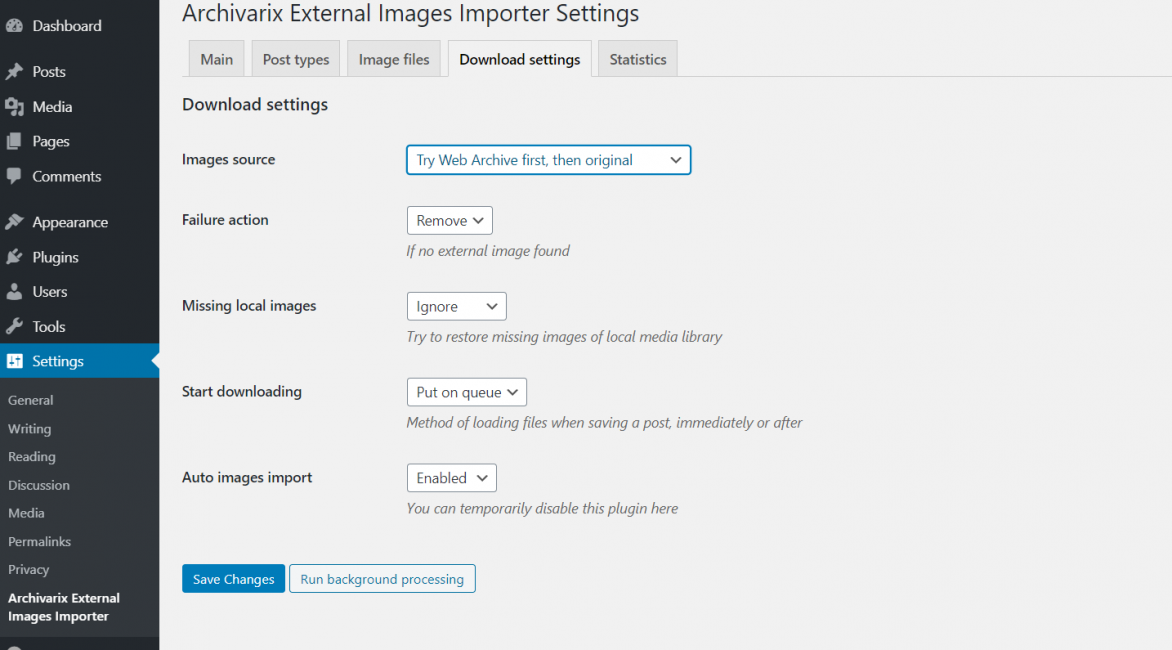
Настройка плагина изображений
Best Internet Wayback Machine Alternative
Let us begin…
Contents
ScreenShots is the another best alternative to the Wayback machine. As its name it works, screenshots just take a snapshot of the websites and save it to the database so you can only access the snapshot. You can not access the code and other things like its destination link and more.
Features:
- Captures screenshots instead of copying domain code
- Easy to use Interface
- Shows complete WHOIS record of the domain ID
Archive.is is one of the best Wayback machine alternatives. The archive comes with great functionality which can not offer others. The archive is getting so much popularity on the internet because of its function, user-friendly and easy navigation. When you visit Archive.is you find two search bar. Archive.is gives you the power to access the content of any websites and also the screenshots of that website.
Features:
- Archives the screenshot and code of a web page
- Has an enormous database
- Allows you to share & download results
- You can archive any website, anytime
iTools is also a certain website and provides you all the information of any domain name. This site accesses the Alexa database. It will also tell you the domain popularity, traffic, and competitors of the website.
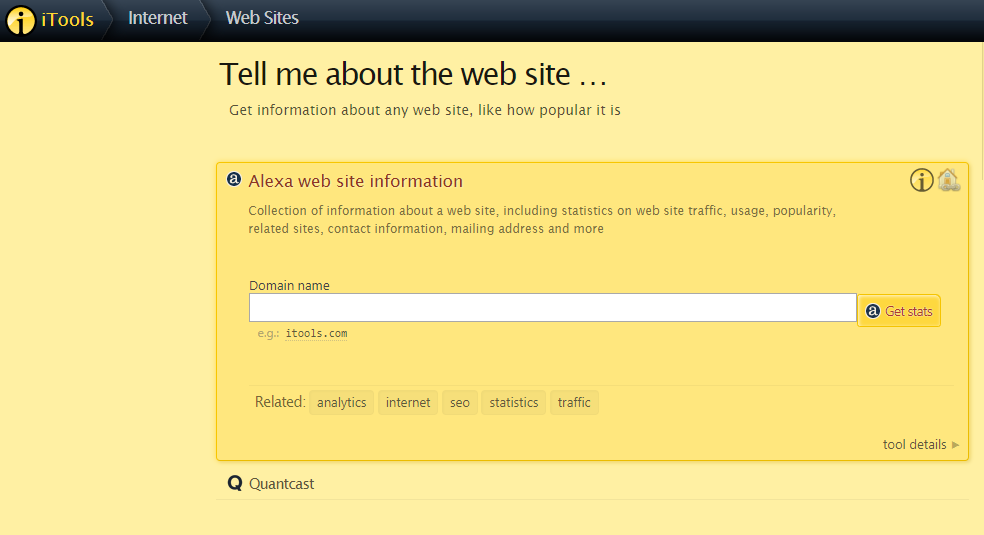
iTools is a slightly different tool from other wayback machine tools in the list as it doesn’t provide any archive option on its homepage. However, you can access it in another way, and to do that, you first need to click the “Internet” tab from its homepage and then on “Website” you need to check the archive for. It also shows you everything important about your competitor to help boost your business.
Features:
- Shows up all information related to domain
- Used to boost your business

Features:
- Shows up detailed information of a domain
- Display transparent results related to your competitor
This site offers you lots of functionality; you can use this to extend your business. You can also use archive content of the website also, and this helps you see your competitors. Moreover, you do not need any special skills. You just need to sign in and get started.
Features:
- Has Online Marketing Tools
- Let’s you archive website content
Editor’s Recommended Alternatives
- Best Dropbox Alternative
- Best Free Game like Minecraft
- Best VLC Alternative
- Best Clash of Clans Alternatives Games
- Best Kindle Alternative eBook Readers
Conclusion
So, readers, These are the Best Wayback Machine Alternative Sites, totally trusted and working so you can use any of them. With the help of these sites, you can check the site history, content and how a website look in past or any deleted content also you can access. If you find any other site better than these, let’s know through comment section.
Edited By: Abhiyanshu Satvat
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
 После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
 Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
 Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page
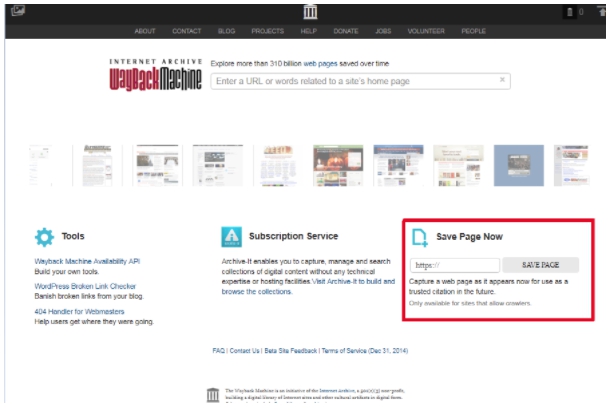 Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
Использование сервиса WebArchive
Всем, кто задается вопросом, где посмотреть старые версии сайтов, можно порекомендовать воспользоваться таким интересным сервисом как WebArchive.
Его функционал гораздо шире, чем у кэша поисковиков, можно просмотреть, как видоизменялся сайт за месяцы и годы своего существования, а также воспользоваться поиском по конкретному числу, когда была сохранена копия содержимого страницы.
Для того, чтобы воспользоваться сервисом, в поиске на сайте WebArchive введите адрес искомой страницы. Также поддерживается поиск по ключевым словам, относящимся к тематике ресурса — можно воспользоваться им. Как только вы это сделаете, появится статистика по годам. Черным цветом отмечено, в какое время создавалась резервная копия сайта, сохраненная в архиве.

Как только вы выберете нужный год и перейдете на него, откроется календарь, в котором можно выбрать число, за которое была сохранена резервная копия страницы сайта.
Зеленым и синим цветом отмечены даты, когда поисковые роботы заархивировали страницу и добавили ее к просмотру.
Как правило, возможность просмотра изображений отсутствует, однако текст сохраняется в полном объеме. А если вы ищете какую-либо конкретную статью на определенном ресурсе, есть вероятность, что ссылка на нее могла сохраниться.
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Donation Process
To find out more about what’s involved with physical donations, Rosenberg suggests going to the Help page for details about shipping instructions or dropping off donations smaller than about 20 boxes. All others are asked to complete a physical item donation form to provide all the information to make a larger donation happen, including where the items are located, an accurate count, and other special considerations for the offer.
Part of the donation of 18,000 records from a collector in Washington D.C.
Once submitted, staff begin the planning process to determine if the collection is in a format that can be accepted, if there are duplicates, and the project timeline. Arrangements then can be made for packing and shipping. In the case of larger collections, the Archive typically is able to provide assistance with transportation costs.
Sometimes donors pack their own items and then the Archive pays for the shipping. That was the case for a recent donation of 18,000 records from a music enthusiast in Washington D.C. The donor was looking for a “forever home” for his beloved vinyl and the Archive was happy to schedule a pickup and preserve the rare collection, Rosenberg said.
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
Как скачать все изменения страницы из веб-архива
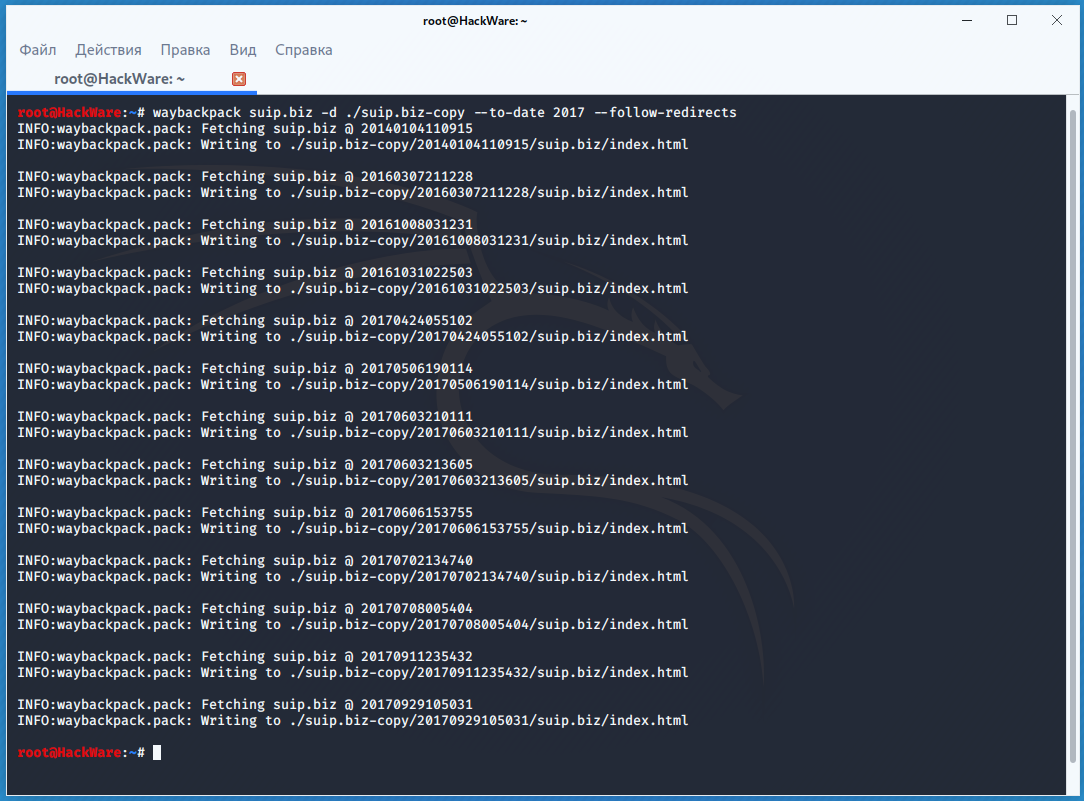
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
waybackpack suip.biz -d ./suip.biz-copy --to-date 2017 --follow-redirects
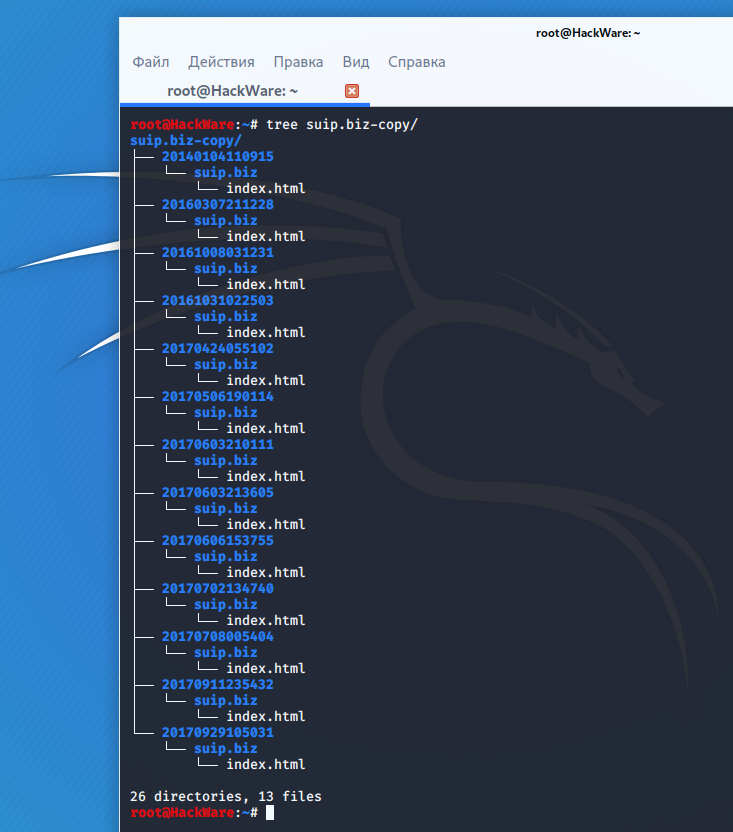
Структура директорий:
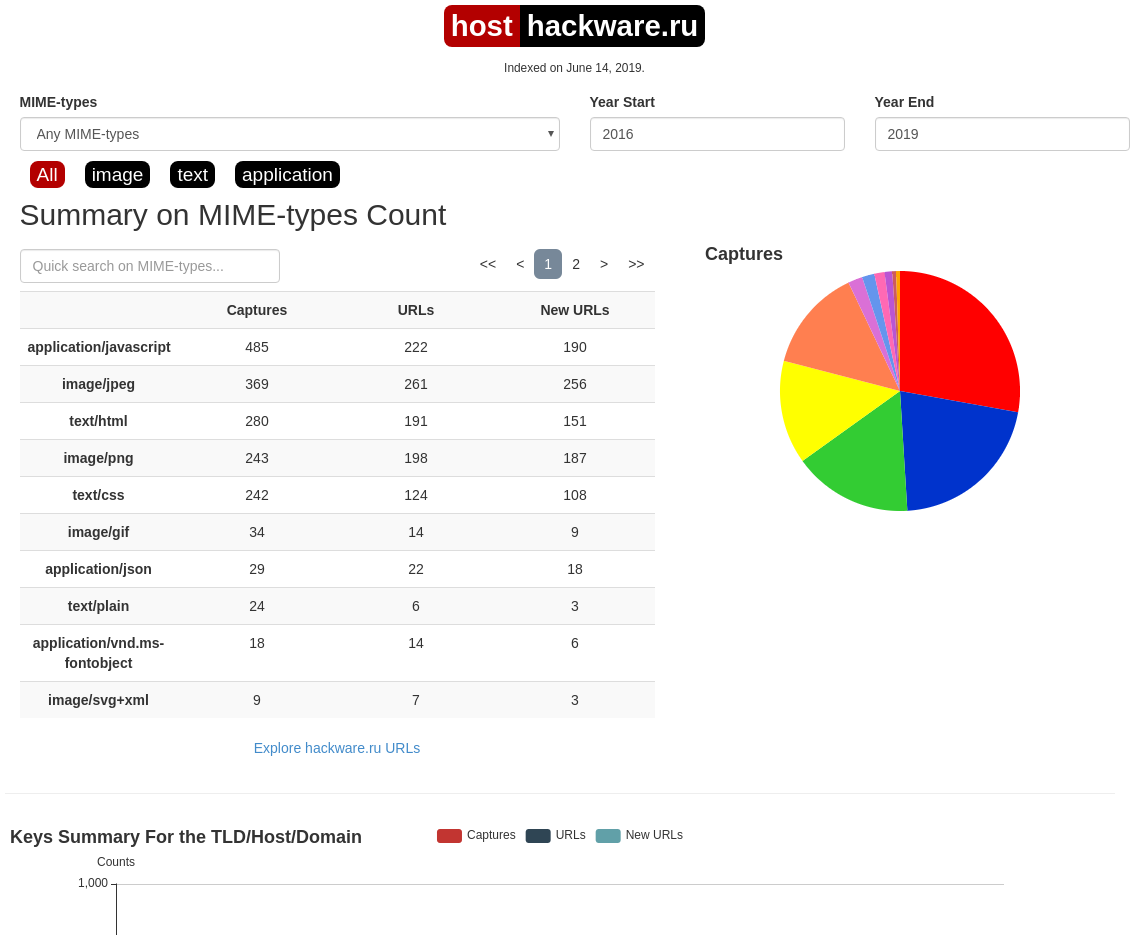
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
waybackpack hackware.ru --list
Примечания
- (англ.). Alexa Internet. — Глобальный рейтинг сайта archive.org. Дата обращения: 20 июня 2020.
- .
- .
- (англ.). archive.org. Дата обращения: 28 марта 2019.
- . Internet Archive (7 мая 2007). Дата обращения: 31 августа 2016.
- (недоступная ссылка). Wayback Machine (6 июня 2000). Дата обращения: 1 сентября 2016.
- Jeff. (Blog). Wayback Machine Forum. Internet Archive (23 сентября 2002). Дата обращения: 4 января 2007. Author and Date indicate initiation of forum thread
- Miller, Ernest (Blog). LawMeme. Yale Law School (24 сентября). Дата обращения: 4 января 2007. The posting is billed as a ‘feature’ and lacks an associated year designation; comments by other contributors appear after the ‘feature’
- Maximillian Dornseif. (англ.). preprint cs/0404005 16. arXiv (2004). Дата обращения: 26 ноября 2017.
- .
- .
- (недоступная ссылка). Дата обращения: 17 сентября 2017.
- . Роскомнадзор (24 октября 2014).
- ↑