Как получить сотни уникальных статей из веб архива
Содержание:
- История создания Internet Archive
- Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
- Восстановление сайта из веб архива
- Бесплатные способы восстановления
- But What if a Page I want to See is not in the Archive?
- Wayback Machine Browser Extension
- Что делать, если удалённая страница не сохранена ни в одном из архивов?
- mydrop.io
- Как найти уникальный контент для своего сайта
- Качаем сайт с web.archive.org
- Восстановление сайта с помощью «Archivarix»
- Как использовать веб-архив?
- Why Donate?
- Что такое веб-архив
- «Archivarix» — оптимальный инструмент для новичков и профессионалов
- How Big is the Wayback Machine Archive?
- Индексация веб-страниц в интернете
- Что такое «Веб Архив»?
- archive.md
- Как проверять полученные статьи на уникальность
- web.archive.org
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org. Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
Я на этом деле конечно уже собаку съел, так что трудностей не возникло. Но прежде, чем закидывать вас инструкциями, давайте повторим сами себе, с чем имеем дело.
Это обычный рекламный вирус, коих стало пруд пруди. И имен у него много: может быть просто WAYBACK MACHINE, а может с дописанной строкой после имени домена WAYBACK MACHINE. В любом случае вирус закидывает вас рекламой, и про ваше любимое казино Вулкан не забывает. До кучи он заражает и свойства ярлыков браузеров.
Кроме того, вирус обожает создавать расписания для запуска самого себя, чтоб жизнь медом не казалась. В результате его деятельности вы вполне можете случайно кликнуть на нежелательную ссылку и скачать себе что-нибудь более серьезное.
Поэтому данный рекламный вирус следует удалять как можно быстрее. Ниже я приведу инструкции по избавлению от вируса WAYBACK MACHINE, но рекомендую использовать автоматизированный вариант.
Восстановление сайта из веб архива
Восстановить удаленный либо взломанный хакерами сайт поможет веб-архив. Восстановление каждой отдельной HTML-страницы проекта слишком трудоемкий процесс, поэтому предпочтительнее использовать специальные программы для парсинга WEB-архива.
Как парсить веб-архив с помощью Robotools
Для скачивания сайта с помощью данного сервиса необходимо выбрать подходящий тариф в зависимости от количества веб-страниц на проекте:
Протестировать работу сервиса можно в , после регистрации будет доступно 25 страниц бесплатно:
Перейдем в раздел «Мои задачи», укажем домен, на котором ранее функционировал нужный сайт и нажмем «Запуск»:
Затем выбираем «Восстановить домен или снимок из веб-архива»:
После этого выбираем нужную дату, количество страниц, действия с внешними ссылками в статьях и нажимаем «Начать процесс восстановления»:
После завершения задачи нажимаем на кнопку для скачивания архива с веб-страницами:
Затем нажимаем «Все ОК, собрать ZIP-архив»:
После этого нажимаем «Скачать архив»:
В данном примере рассматривалось восстановление сайта на WordPress, получен архив с такими файлами:
Как скачать сайт из веб-архива с помощью Archivarix
Этот сервис также помогает восстановить старые версии сайтов из веб-архива. Цены зависят от количества файлов на проекте. Начнем работу с выбора раздела «Восстановить из веб-архива». Укажем домен и при желании установим временной диапазон, в правой колонке отметим дополнительные параметры восстанавливаемого проекта:
Затем укажем электронный адрес и нажмем «Восстановить»:
Если сайт содержит более 200 файлов, придет уведомление на почту с предложением оплатить восстановление проекта:
Бесплатные способы восстановления
Ручной
Собственно основной ресурс, который используют все сервисы для восстановления сайта это https://archive.org/web/
Ниже отображается календарь за выбранный год, там вы можете увидеть конкретный месяц и день, когда был произведен снимок.
Кликайте по снимку, откроется окно со страницей сайта за тот день. Открываете консоль разработчика и копируете html и все ресурсы необходимые странице — картинки, css, js и др. Неблагодарное дело.
Аналоги archive.org
https://archive.org/web/ не единственый проект, который делает снимки сайтов и хранит их. Существуют и другие напримерArchive.ishttp://timetravel.mementoweb.org/ уникальный проект, своего рода гугл по сайтам-аналогам archive.org
Веб кэш
Если нужно восстановить данные сайта, которые были потеряны недавно, может подойти кэш поисковой системы Гугл. Можно попробовать тут https://thisis-blog.ru/posmotret-sajt-v-keshe/
Библиотеки
Можно развернуть и свою поделку под свои нужды, если есть возможность. На гитхабе ищется по ключу wayback-machine
Что там можно найти, примеры:
https://pypi.org/project/wayback-scraper/https://github.com/sangaline/wayback-machine-scraperhttps://github.com/hartator/wayback-machine-downloader
Делитесь своим опытом использования данных сервисов. Если нашли ошибку, либо есть что добавить, тоже пишите.
But What if a Page I want to See is not in the Archive?
Firstly… don’t panic!
It would be a pain a page you wanted to examine was not in the archive. Especially if you wanted to do some of the research I’ve discussed above. The Wayback Machine homepage has a tool that you can use to snapshot a page immediately though. Of course this won’t help to examine a particular issue in the past. But you could at least start archiving the site so it’s available in future.
Type the page URL into the “Save Page Now” box and Wayback Machine will add it to the archive immediately.
The tool will save the page along with any images and CSS it finds there. However, it will not crawl any links it finds on the page and so will not archive the whole domain.
You can add more pages to the archive from a site, but you have to use the “Save Page Now” tool for each one.
If you have concerns about privacy, archive.org does not retain IP addresses on submissions you make to it. So whenever you use the tool your activity is anonymous.
One final note. When a page is archived there is no guarantee when it will be snapshotted again. So you might return to the site again and see only the version that you submitted. Having said this, Wayback Machine will revisit archived pages at some point and the calendar will show this.
Wayback Machine Browser Extension
The Wayback Machine also has an official browser extension for Google Chrome. Using it to archive web pages is super easy. Simply navigate to a page you want to archive, click on the Wayback Machine icon in your toolbar and click “Save Page Now.”
In addition to making it even easier to save pages, the browser extension has another nifty trick up ts sleeve. Have you ever clicked on a link only to be confronted by a vague 404 error message? Whether it is a valuable source for your research paper or a really good recipe, it can be incredibly frustrating. With the Wayback Machine extension installed, that frustration could turn into a sigh of relief. When your browser runs into a dead end, the extension will search the archive to see if there is a saved copy on the Wayback Machine. If there is, it will ask you if you would like to visit that page.
If you don’t use Chrome, don’t fret. There is a Wayback Machine extension available for Firefox; however, it is still a work in progress. Additionally, there are plans to develop an extension for Safari users as well.
Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
Например:
cache:https://hackware.ru/?p=6045
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=1&vwsrc=0
Исходный код:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=0&vwsrc=1
mydrop.io
(реф. ссылка)
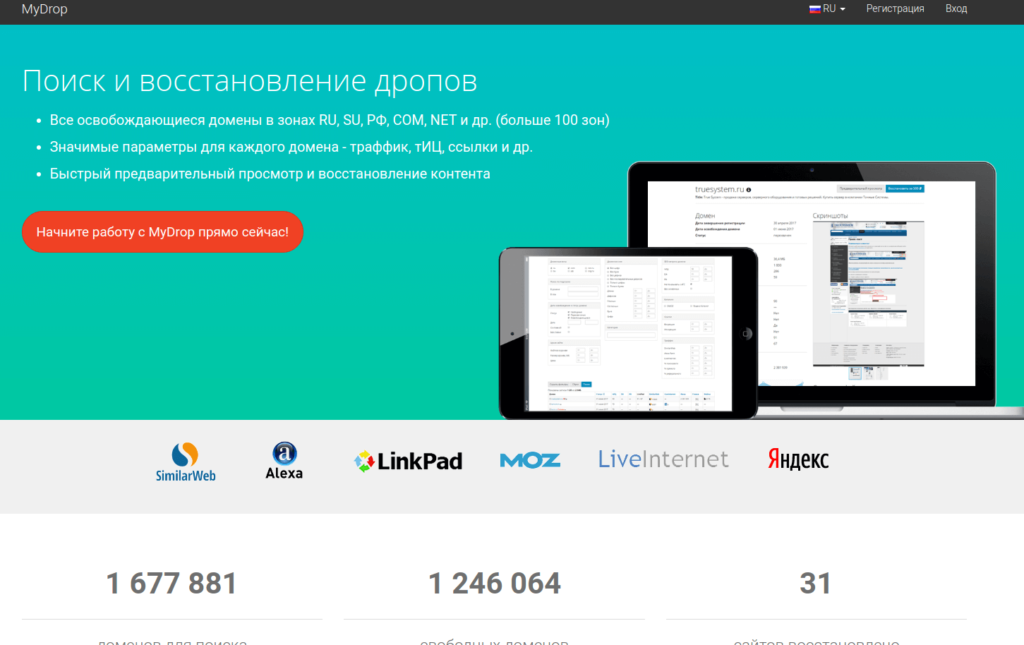
Удобный сервис, кроме фнкционала восстановления контента сайта имеет фунционал поиска доменов по различным параметрам. Пользуюсь им больше года.
Из преимуществ:
- широкий набор фильтров для поиска домена
- возможность подписки на фильтр
- информативная таблица доменов с полезными seo метрикам( TF, CF, DA, PA, LinkPad, SimilarWeb, LiveInternet, Alexa)
- показывают кол-во файлов, которые восстановить и размер в МБ
- показывают, есть ли ставки на домен через сервис expired.ru
- Есть своя Cms
- адекватные цены
- скидки при пополнении счета от 3000 руб.
- интерфейс на русском
Из минусов:
- нет пробного периода либо бесплатного восстановления, если восстонавливаемый сайт «небольшой»
- есть функционал предварительного просмотра, но он очень сыроват и на счета должна быть сумма не меньше чем стоимость восстановления
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Восстановление сайта с помощью «Archivarix»
После выбора наиболее приемлемого тарифного плана можно приступить к самому главному, именно — восстановлению некогда преданного забвению веб-ресурса.
Кроме того, «Архиварикс» может скачивать и восстанавливать не только сайт из Веб Архива, но и тех. которые на момент скачивания являются рабочими — находятся в режиме онлайн, именно это и есть ключевое отличие данного сервиса от всевозможных «парсеров», а также различного рода «качалок».
Главная задача «Архиварикса» состоит в восстановлении полностью функциональной и работоспособной версии сайта, дабы тот мог полноценно использоваться на сервере пользователя.
Archivarix
Приступим к обзору первого модуля, отвечающего за восстановление сайта из Архива. Чтобы воспользоваться им, необходимо перейти по адресу: https://ru.archivarix.com/
Далее необходимо заполнить все пункты, находящиеся на странице.
А именно:
- Вспомнить и ввести корректное название доменного имени, например: «пример-сайта.рф».
- Выбрать актуальную версию сайта, указав необходимую дату «до определенной временной отметки» или наоборот, «начиная с определенной временной отметки». Если оставить данный пункт незаполненным, то пользователь получить наиболее актуальную версию веб-сайта.
- В третьей строке необходимо указать действующий и рабочий адрес электронной почты, на который впоследствии придет важная информация — уведомление и ссылка на скачивание архива.
- Для продвинутых пользователей была предусмотрены опции «Рекомендуемые/Продвинутые/Встроенные параметры», благодаря которым можно произвести тонкую настройку различных параметров.
- Нажимаем клавишу «Восстановить», разобравшись предварительно со всеми предыдущими пунктами и параметрами.
После этого система займется сбором и упорядочиванием всей необходимой информации и компонентов сайта, после этого «Архиварикс» сформирует письмо, в котором будет детально указан результат анализа полученных данных: размер сайта, количество файлов, типы данных в фактическом и процентном соотношении.
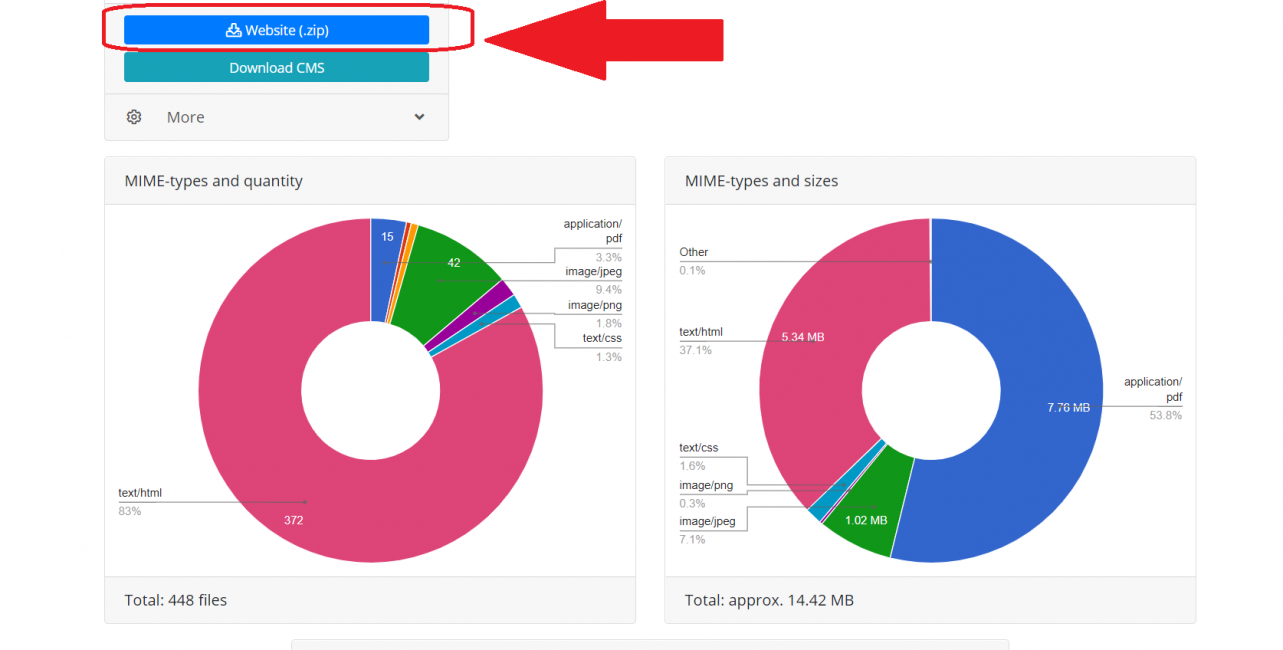
Информация о сайте, собранная Архивариксом
Чтобы скачать восстановленную копию сайта в zip-архиве — необходимо нажать на кнопку «Website (.zip)», расположенную в верхнем левом углу (как показано на скриншоте выше).
Как использовать веб-архив?
 Форма для поиска информации на Peeep.us
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Why Donate?
For donations of 50 or more items, the Archive can create a collection to both honor the donor and make their donation accessible all in one place. “The ability to access all of their media in one place really reassures our donors that they will still have access to their items even once they’re no longer in their physical possession,” said Rosenberg. Some stories behind major contributions are covered by the Archive in its blog.
Better World Books, a socially responsible bookstore that has a longstanding relationship with the Internet Archive, regularly donates books for preservation and digitization. It receives many of its books from library partners around the world. The Archive accepts many materials that BWB will not.
Internet Archive team members having fun with the task of packing & shipping an entire library collection from Bay State College.
“We love more than anything to get large collections—entire intellectual units, such as a reference collection that is curated,” said Chris Freeland, a librarian who works at the Archive. “It helps us round out our collection, and helps our patrons. If someone has a collection that no longer fits their collection development priorities, think of Better World Book or the Internet Archive for those materials.”
The Archive is open to over-sized items, such as maps, and books that do not have to have an ISBN number. What about loose periodicals? The Archive does not want a few scattered issues but does have interest in long runs of a magazine.
Once digitized, patrons with print disabilities can access the materials and some are selected to be accessible via Controlled Digital Lending and for machine learning research. Together, we can achieve long term preservation and access to our collective cultural legacy.
Что такое веб-архив
Веб-архив сайтов позиционируется как своеобразная бесплатная машина времени, позволяющая вернуться на месяцы или годы назад, чтобы увидеть, как выглядел ресурс на тот момент. При этом у каждого сайта сохраняются многочисленные версии от разных дат, которые зависят от посещений проекта краулерами веб-архива. У популярных сайтов может сохраняться тысячи версий, которые обновлялись ежедневно множество раз на протяжении всего периода существования проекта:
Веб-архив основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
«Archivarix» — оптимальный инструмент для новичков и профессионалов
«Archivarix» представляет собой бесплатную СМS, которая имеет открытый исходный код, а также онлайн-загрузчик и восстановитель веб-сайтов из «Веб Архива».
И это — ключевое преимущество «Archivarix», ведь чтобы восстановить удаленный ресурс самостоятельно (из Веб Архива) необходимо владеть языками веб-программирования и иметь определенный опыт в сайтостроении, тогда как «Archivarix» предлагает восстановление и загрузку работоспособной копии удаленного сайта буквально в «один клик»!
Кроме автоматизации и простоты сервис может похвастаться доступной ценовой политикой.
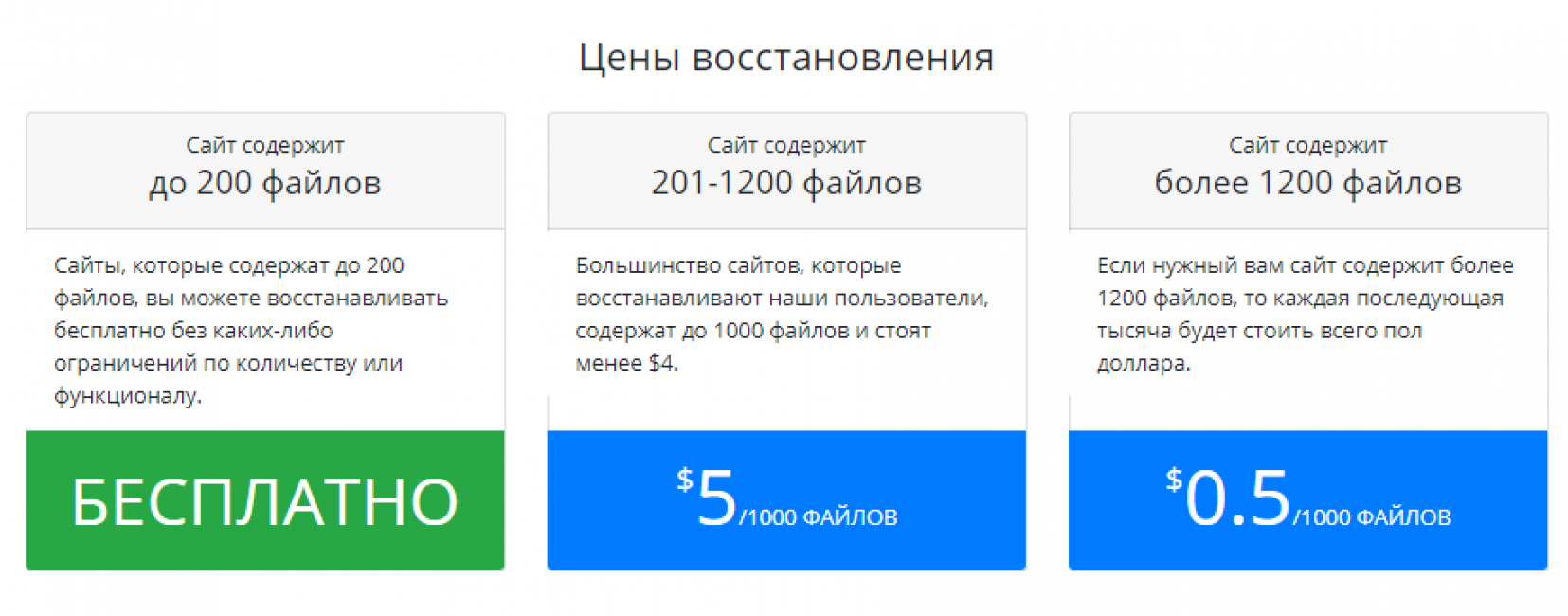
Тарифные планы сервиса Archivarix
Тарифный план: Бесплатно
Однако при условии, что восстанавливаемый сайт содержит не более двух сотен файлов в своем составе, при этом каких-либо ограничений по функционалу сервис не устанавливает. Восстанавливать можно такие сайты можно без каких-либо ограничений по количеству и времени.
Данный тарифный план идеально подойдет для новичков, потому как позволит оценить функционал сервиса и его преимущества непосредственно на практике. А еще этот тариф подойдет тем пользователям, о которых говорится в самом начале данной статьи. Обладатели некогда удаленных личных дневников и блогов (некоммерческой направленности, ведь зачастую именно такие сайты содержат малое число файлов) смогут совершено бесплатно и полностью восстановить свой ресурс, а заодно и бесценные воспоминания.
Тарифный план: $5 за 1000 файлов
Восстановление удаленных сайтов, которые содержат в своем составе от 201 до 1200 файлов (а таких по статистике — подавляющее большинство), попадают под действие второго тарифа, в котором стоимость за 1000 файлов составляет 5 долларов США.
Справедливости ради стоит отметить, что стоимость взимается за количество файлов (по факту). Иными словами, если ресурс имеет в своем наличии, например, 800 файлов, то и стоимость будет немногим менее пяти долларов.
Тарифный план: $0,5 за 1000 файлов
Бывшие владельцы крупных информационных порталов, статейников и/или новостных ресурсов, а также других типов сайтов, содержащих в себе 1200 файлов и более, могут воспользоваться последним тарифом.
Он предусматривает стоимость 0,5 долларов США за каждую 1000 файлов, при условии что восстанавливаемый веб-ресурс «вмещает» не менее 1200.
How Big is the Wayback Machine Archive?
The current estimate is that it contains over 362 billion archived web artifacts since its inception.
Wayback Machine Archived Artifacts Grouped by Type
The pie chart clearly shows that web pages make up the majority of the Archive. They represent 91.24% of the total number of artifacts documented.
This is an enormous archive… but clearly not as large as Google’s index, which includes 100s of trillions of indexed pages.
However, the Wayback Machine can show you a number of different past versions of a particular web page. Google’s index does not do this.
The great thing about this is you can run a Wayback Machine search on any website to see how its content has changed. Assuming of course it is present in the archive in the first place.
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
Что такое «Веб Архив»?
Перед тем, как преступить к обзору сервиса «Archivarix», следует вкратце ознакомиться с так называемым «Веб Архивом», дабы понять что он собой представляет. Итак, «Веб Архив» (официально — Интернет Архив) представляет собой организацию некоммерческого типа, которая ведет свою деятельность с 1996 года.
Данная организация занимается сбором копий интерне-страниц, включая размещенный на них контент:
- статьи;
- фотографии;
- изображения (в том числе анимацию);
- видео и аудио;
- программное обеспечение;
- а также иную информацию.
А общий размер базы составляет (по состоянию на 2019 год) около 45 петабайт, при этом количество сохраненных копий веб-страниц достигло рекордной и беспрецедентной отметки в 502 млрд!
В отличие от кеша поисковых систем (который так же содержит сохраненные копии веб-ресурсов), «Веб Архив» обеспечивает долгосрочное хранение файлов и информации, а также имеет юридический статус библиотеки (с 2007 года).
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.
Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».
Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
web.archive.org


В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
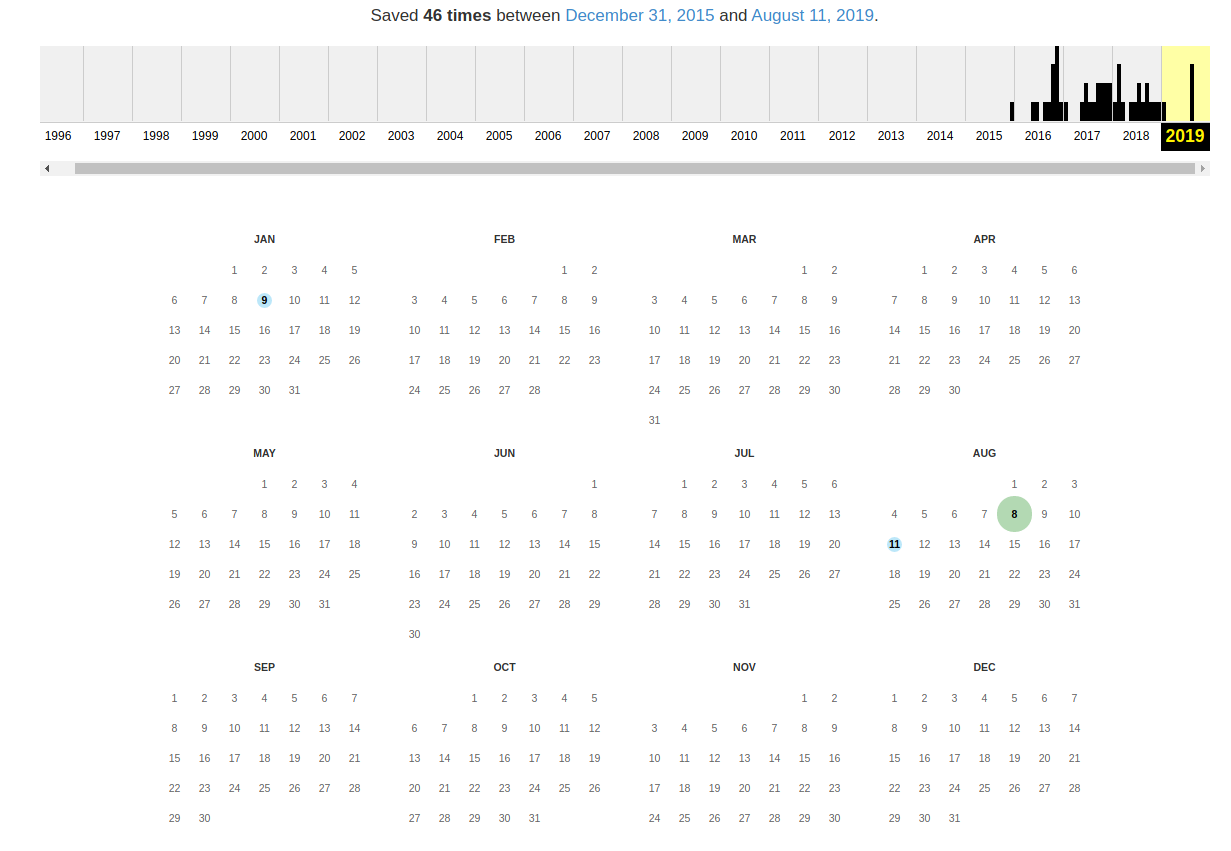
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.


Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
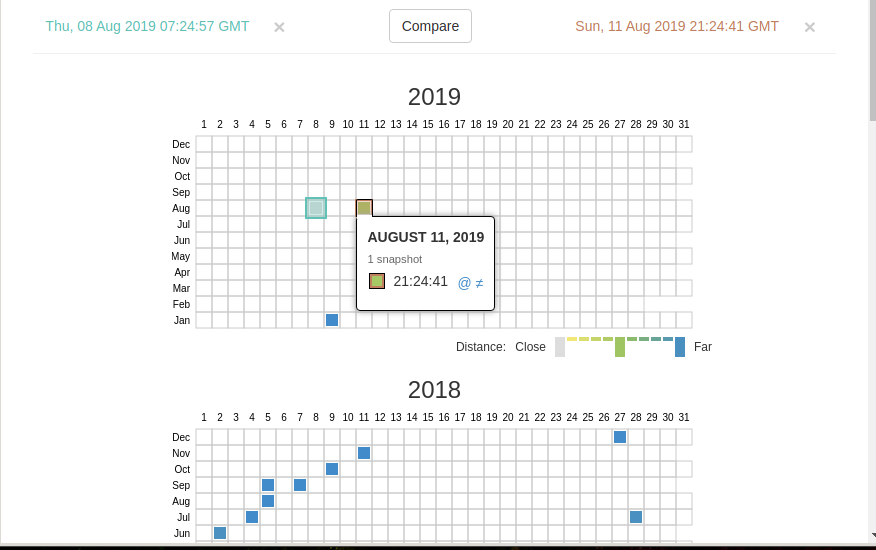
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
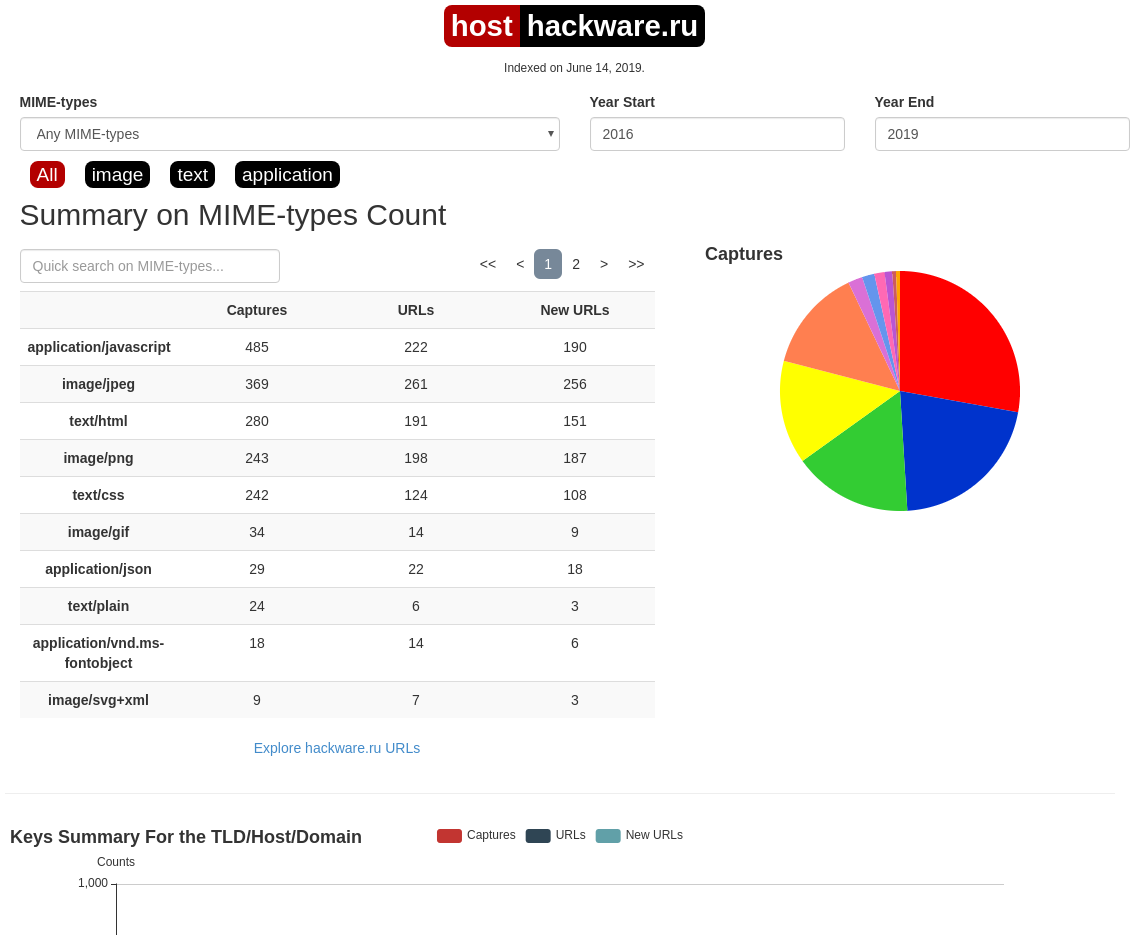
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.