Как парсить сайт: 20+ инструментов на все случаи жизни
Содержание:
- Пример использования#
- static defaultConf#
- async parse(set, results)#
- Зачем нужны парсеры
- await this.cookies.*#
- BatchURLScraper
- Виды парсеров по технологии
- Парсите страницы сайтов в структуры данных
- Популярные парсеры для SEO
- Парсеры сайтов в зависимости от используемой технологии
- Проблема урлов картинок и ссылок
- Парсеры поисковых систем#
Пример использования#
Разберем на примере парсера :
- парсер делает скриншоты сайтов указанного размера, а также может уменьшать(масштабировать) картинку
- может опционально использовать прокси
- создает отдельную вкладку браузера на каждый поток A-Parser’а
import{BaseParser,PuppeteerTypes}from’a-parser-types’;
let browserPuppeteerTypes.Browser;
let jimp;
classJS_Chrome_ScreenshotsMaker2extendsBaseParser{
static defaultConftypeofBaseParser.defaultConf={
version’0.2.1′,
results{
flat
‘screenshot’,’PNG screenshot’,
},
results_format’$screenshot’,
load_timeout30,
width1024,
height768,
log_screenshots,
headless1,
};
static editableConftypeofBaseParser.editableConf=
‘log_screenshots’,’checkbox’,’Log Screenshots’,
‘width’,’textfield’,’Viewport Width’,
‘height’,’textfield’,’Viewport Height’,
‘resize_width’,’textfield’,’Resize Width’,
‘resize_height’,’textfield’,’Resize Height’,
‘headless’,’checkbox’,’Chrome Headless’,
;
asyncinit(){
browser =awaitthis.puppeteer.launch({
headlessthis.conf.headless,
logConnectionsfalse,
defaultViewport{
widthparseInt(this.conf.width),
heightparseInt(this.conf.height),
}
});
if(this.conf.resize_width){
jimp =require(‘jimp’);
};
};
asyncdestroy(){
if(browser)
await browser.close();
}
pagePuppeteerTypes.Page;
asyncthreadInit(){
this.page=await browser.newPage();
awaitthis.page.setCacheEnabled(true);
awaitthis.page.setDefaultNavigationTimeout(this.conf.timeout*1000);
awaitthis.puppeteer.setPageUseProxy(this.page);
this.logger.put(`New page created for thread #${this.threadId}`);
}
asyncparse(set, results){
const self =this;
const{conf, page}= self;
for(let attempt =1; attempt <= conf.proxyretries; attempt++){
try{
self.logger.put(`Attempt #${attempt}`);
await page.goto(set.query);
await page.evaluate(()=>{document.querySelector(‘html’).style.overflow=’hidden’;});
results.screenshot=await page.screenshot();
if(parseInt(conf.resize_width)){
let image =await jimp.read(results.screenshot);
image.resize(parseInt(conf.resize_width),parseInt(conf.resize_height));
results.screenshot=await image.getBufferAsync(‘image/png’);
}
self.logger.put(`Screenshot(${attempt}): OK, size: ${parseInt(«»+(results.screenshot.length 1024))}KB`);
if(conf.log_screenshots)
self.logger.putHTML(«<img src=’data:image/png;base64,»+ results.screenshot.toString(‘base64’)+»‘>»);
results.success=1;
await self.puppeteer.closeActiveConnections();
break;
}
catch(error){
self.logger.put(`Fetch page error: ${error}`);
await self.puppeteer.closeActiveConnections();
await self.proxy.next();
}
}
return results;
}
}
Скопировать
Данный пример демонстрирует простоту использования разных прокси для каждой вкладки, а также многопоточную работу(1 поток = 1 вкладка браузера)
static defaultConf#
static defaultConf ={
version’0.0.1′,
results{
flat
‘title’,’Title’,
,
arrays{
}
},
results_format»Title: $title\n»,
exampleKey’value’,
};
Скопировать
Конфигурация парсера по умолчанию, конфиг будет доступен в объекте класса через свойство , обязательными являются следующие поля:
-
— описывает в декларативном стиле результаты, которые может возвращать данный парсер
-
— задает формат результата по умолчанию
Все остальные поля являются опциональными, существует следующий список параметров, которые влияют на работу парсера:
| Название параметра | Тип | Описание(значение по умолнанию) |
|---|---|---|
| timeout | Максимальное время ожидания запроса в секундах() | |
| useproxy | Определяет использовать ли прокси() | |
| max_size | Максимальный размер файла результата() | |
| proxyretries | Количество попыток на каждый запрос, если запрос не удаётся выполнить за указанное число попыток то он считается неудачным и пропускается() | |
| requestdelay | Задержка между запросами в секундах() | |
| proxybannedcleanup | Время бана прокси в секундах() | |
| pagecount | Количество страниц парсинга() | |
| parsecodes | Значение кодов ответов для запросов которые будут считаться успешными() | |
| queryformat | Формат запроса() |
async parse(set, results)#
Метод реализует основную логику обработки запроса и получения результата парсинга, в качестве аргументов передаются:
-
— объект с информацией о запросе:
- — текстовая строка запроса
- — уровень запроса, по умолчанию
-
— объект с результатами, которые необходимо заполнить и вернуть из метода parse()
- парсер должен проверять наличие каждого ключа в объекте results и заполнять его только при наличии, таким образом оптимизируется скорость и парсятся только те данные, которые используются в формировании результата
- содержит ключи необходимых flat переменных со значением , по умолчанию это означает что результат не получен, а также ключи переменных-массивов(arrays) со значением в виде пустого массива, готового для заполнения
- должен устанавливаться в значение при успешной обработке запроса, по умолчанию значение , означающее что запрос обработан с ошибкой
Разберем на примере:
classJS_HTML_TagsextendsBaseParser{
static defaultConf ={
results{
flat
‘title’,’Title’,
,
arrays{
h2’H2 Headers List’,
‘header’,’Header’,
,
}
},
…
};
asyncparse(set, results){
const{success, data, headers}=awaitthis.request(‘GET’,set.query);
if(success &&typeof data ==’string’){
let matches;
if(results.title&& matches = data.match(<title*>(.*?)<\/title>))
results.title= matches1;
if(results.h2){
let count =;
const re =<h2*>(.*?)<\/h2>g;
while(matches = re.exec(data)){
results.h2.push(matches1);
}
}
results.success=1;
}
return results;
}
};
Скопировать
Обратите внимание что вы можете создавать собственные функции и методы для лучшей организации кода:
functionAnswer(){
return42;
}
classJS_HTML_TagsextendsBaseParser{
…
asyncparse(set, results){
results =awaitthis.doWork(set, results);
return results;
}
asyncdoWork(set, results){
results.answer=Answer();
return results;
}
};
Скопировать
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Работа с cookies для текущего запроса
Получение массива cookies
awaitthis.cookies.getAll();
Скопировать
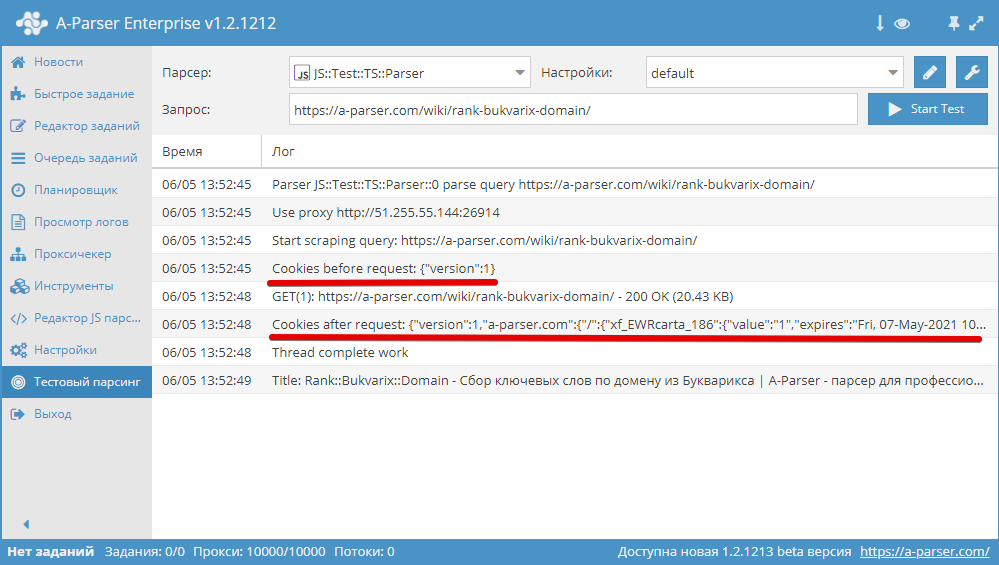
Установка cookies, в качестве аргумента должен быть передан массив с cookies
asyncparse(set, results){
this.logger.put(«Start scraping query: «+set.query);
awaitthis.cookies.setAll(‘test_1=1′,’test_2=2’);
let cookies =awaitthis.cookies.getAll();
this.logger.put(«Cookies: «+JSON.stringify(cookies));
results.SKIP=1;
return results;
}
Скопировать

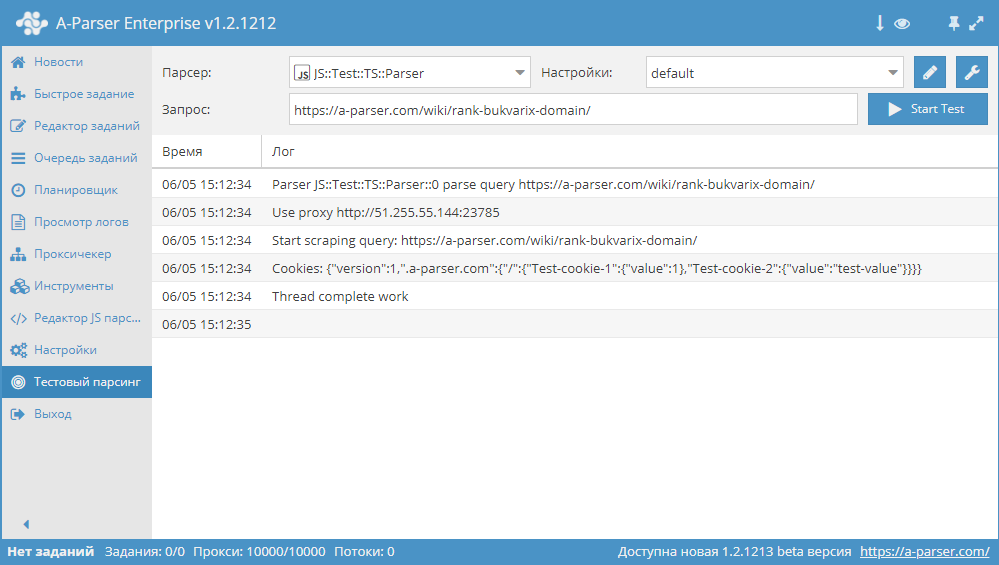
— установка одиночного cookie
asyncparse(set, results){
this.logger.put(«Start scraping query: «+set.query);
awaitthis.cookies.set(‘.a-parser.com’,’/’,’Test-cookie-1′,1);
awaitthis.cookies.set(‘.a-parser.com’,’/’,’Test-cookie-2′,’test-value’);
let cookies =awaitthis.cookies.getAll();
this.logger.put(«Cookies: «+JSON.stringify(cookies));
results.SKIP=1;
return results;
}
Скопировать
BatchURLScraper
Существует множество инструментов, позволяющих осуществлять скрейпинг (извлекать данные из веб-сайтов), однако большинство из них платные и громоздкие, что несколько ограничивает их доступность для массового использования.
Поэтому нами был создан простой и бесплатный инструмент – BatchURLScraper, предназначенный для сбора данных из списка URL с возможностью экспорта полученных результатов в Excel.

Интерфейс программы достаточно прост и состоит всего из 3-х вкладок:
- Вкладка «Список URL» предназначена для добавления страниц парсинга и отображения результатов извлечения данных с возможностью их последующего экспорта.
- На вкладке «Правила» производится настройка правил скрейпинга при помощи XPath, CSS-локаторов, XQuery, RegExp или HTML templates.
- Вкладка «Настройки» содержит общие настройки программы (число потоков, User-Agent и т.п.).


Также нами был добавлен модуль для отладки правил.

При помощи встроенного отладчика правил можно быстро и просто получить HTML-содержимое любой страницы сайта и тестировать работу запросов, после чего использовать отлаженные правила для парсинга данных в BatchURLScraper.
Разберем более подробно примеры настроек парсинга для различных вариантов извлечения данных.
Виды парсеров по технологии
Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
- Parsers;
- Scraper;
- Data Scraper;
- Kimono.
Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, ParserOK. В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
Эти формулы: IMPORTXML и IMPORTHTML.
IMPORTXML
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Вот так выглядит функция:
Функция принимает два значения:
- ссылку на страницу или фид, из которого нужно получить данные;
- второе значение — XPath-запрос (специальный запрос, который указывает, какой именно элемент с данными нужно спарсить).
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: Копировать → Копировать XPath.

С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
IMPORTHTML
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
Она принимает три значения:
- Ссылку на страницу, с которой необходимо собрать данные.
- Параметр элемента, который содержит нужные данные. Если хотите собрать информацию из таблицы, укажите «table». Для парсинга списков — параметр «list».
- Число — порядковый номер элемента в коде страницы.
Парсите страницы сайтов в структуры данных
Что такое Диггернаут и что такое диггер?

Диггернаут — это облачный сервис для парсинга сайтов, сбора информации и других ETL (Extract, Transform, Load) задач. Если ваш бизнес лежит в плоскости торговли и ваш поставщик не предоставляет вам данные в нужном вам формате, например в csv или excel, мы можем вам помочь избежать ручной работы, сэкономив ваши время и деньги!
Все, что вам нужно сделать — создать парсер (диггер), крошечного робота, который будет парсить сайты по вашему запросу, извлекать данные, нормализовать и обрабатывать их, сохранять массивы данных в облаке, откуда вы сможете скачать их в любом из доступных форматов (например, CSV, XML, XLSX, JSON) или забрать в автоматическом режиме через наш API.
Какую информацию может добывать Диггернаут?

- Цены и другую информацию о товарах, отзывы и рейтинги с сайтов ритейлеров.
- Данные о различных событиях по всему миру.
- Новости и заголовки с сайтов различных новостных агентств и агрегаторов.
- Данные для статистических исследований из различных источников.
- Открытые данные из государственных и муниципальных источников. Полицейские сводки, документы по судопроизводству, росреест, госзакупки и другие.
- Лицензии и разрешения, выданные государственными структурами.
- Мнения людей и их комментарии по определенной проблематике на форумах и в соцсетях.
- Информация, помогающая в оценке недвижимости.
- Или что-то иное, что можно добыть с помощью парсинга.
Должен ли я быть экспертом в программировании?

Если вы никогда не сталкивались с программированием, вы можете использовать наш специальный инструмент для построения конфигурации парсера (диггера) — Excavator. Он имеет графическую оболочку и позволяет работать с сервисом людям, не имеющих теоретических познаний в программировании. Вам нужно лишь выделить данные, которые нужно забрать и разместить их в структуре данных, которую создаст для вас парсер. Для более простого освоения этого инструмента, мы создали серию видео уроков, с которыми вы можете ознакомиться в документации.
Если вы программист или веб-разработчик, знаете что такое HTML/CSS и готовы к изучению нового, для вас мы приготовили мета-язык, освоив который вы сможете решать очень сложные задачи, которые невозможно решить с помощью конфигуратора Excavator. Вы можете ознакомиться с документацией, которую мы снабдили примерами из реальной жизни для простого и быстрого понимания материала.
Если вы не хотите тратить свое время на освоение конфигуратора Excavator или мета-языка и хотите просто получать данные, обратитесь к нам и мы создадим для вас парсер в кратчайшие сроки.
Популярные парсеры для SEO
PromoPult
Данный парсер метатегов и заголовков позволяет убрать дубли метатегов, а также выявить неинформативные заголовки, будучи особо полезным при анализе SEO конкурентов. Первые пятьсот запросов – бесплатно, а далее придется заплатить 0,01 рубля за запрос при объеме от десяти тысяч.
Работа сервиса происходит «в облаке», а для начала потребуется добавить список URL и указать страницы, парсинг которых следует осуществить. Благодаря данному парсеру можно проанализировать ключевые слова, используемые конкурентами с целью оптимизации страниц сайта, а также изучить, как происходит формирование заголовков.
Предназначен для комплексного анализа сайтов, что позволяет провести анализ основных SEO-параметров, осуществить технический анализ сайта, а также импортировать данные как из Google Аналитики, так и Яндекс.Метрики. Предоставляется тестовый период длительностью в 14 дней, а стоимость начинается от 19 долларов в месяц.
Screaming Frog SEO Spider
Данный парсер является идеальным решением для любых SEO-задач. Лицензию на год можно приобрести за 149 фунтов, однако есть и бесплатная версия, отличающаяся ограниченным функционалом, в то время как количество URL для парсинга не может превышать отметку в пятьсот.
ComparseR
С помощью данного десктопного парсера можно выявить страницы, которые обходит поисковый робот во время сканирования сайта, а также провести технический анализ портала. Есть демоверсия с некоторыми ограничениями, а лицензию можно приобрести за две тысячи рублей.
Анализ от PR-CY
Представляет собой онлайн-ресурс для анализа сайтов по достаточно подробному списку параметров. Минимальный тариф составляет 990 рублей в месяц, а тестирование, с полным доступом к функционалу, можно провести в течение семи дней.
Анализ от SE Ranking
Стоимость минимального тарифа данного облачного сервиса составляет от семи долларов в месяц, при оформлении годовой подписки, причем возможна как подписка, так и оплата за каждую проверку. Сервис позволяет проверить скорость загрузки страниц, проанализировать метатеги. Выявить технические ошибки, а также провести анализ внутренних ссылок.
Xenu`s Link Sleuth
Данный бесплатный десктопный парсер предназначен для Windows и используется для парсинга всех URL, имеющихся на сайте, а также применяется с целью обнаружения неработающих ссылок.
Представляет собой SEO-комбайн, отличающийся многофункциональностью, причем минимальный тарифный план лицензии, носящей пожизненный характер, составляет 119 долларов, в то время как максимальный – 279. Демоверсия присутствует. Данный инструмент позволяет осуществить парсинг ключевых слов и провести мониторинг позиций, занимаемых сайтом в поисковых системах.
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Проблема урлов картинок и ссылок
Как вам должно быть известно, существуют абсолютные пути и относительные. Пример: ссылка http://site.ru/folder/subfolder/page.html — абсолютная, а ссылка folder/subfolder/page.html — относительная.
Учтите, что то, куда ведет относительная ссылка, зависит от той страницы, где она расположена. Давайте разберемся более подробнее.
Пример: мы парсим страницу сайта, url страницы http://site.ru/folder/subfolder/index.html.
На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/77270.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/folder/subfolder/image.png. Давайте разберем все возможные варианты.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/75516.png» — с начальным слешем (эта ссылка тоже абсолютная, только без http в начале). В этом случае реальный абсолютный путь к картинке такой: http://site.ru/image.png.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/59157.png».
В этом случае реальный абсолютный путь к картинке такой: http://site.ru/folder/subfolder/images/image.png.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/45053.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/images/image.png.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/7676.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/folder/image.png, так как конструкция ../ поднимает нас на папку выше.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/41032.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/image.png, так как конструкция ../../ поднимает нас на две папки выше.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/80277.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/folder/image.png, так как конструкция ../ поднимает нас на две папки выше.
Думаю, вам понятно, что в данном случае разницы между картинками и ссылками никакой нет — все пути строятся одинаково. То же самое относится к путям к CSS файлам, если они вам вдруг понадобятся (всякое бывает).
В общем, я думаю, общая логика ясна.
Парсеры поисковых систем#
| Название парсера | Описание |
|---|---|
| SE::Google | Парсинг всех данных с поисковой выдачи Google: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Многопоточность, обход ReCaptcha |
| SE::Yandex | Парсинг всех данных с поисковой выдачи Yandex: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Максимальная глубина парсинга |
| SE::AOL | Парсинг всех данных с поисковой выдачи AOL: ссылки, анкоры, сниппеты |
| SE::Bing | Парсинг всех данных с поисковой выдачи Bing: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Dogpile | Парсинг всех данных с поисковой выдачи Dogpile: ссылки, анкоры, сниппеты, Related keywords |
| SE::DuckDuckGo | Парсинг всех данных с поисковой выдачи DuckDuckGo: ссылки, анкоры, сниппеты |
| SE::MailRu | Парсинг всех данных с поисковой выдачи MailRu: ссылки, анкоры, сниппеты |
| SE::Seznam | Парсер чешской поисковой системы seznam.cz: ссылки, анкоры, сниппеты, Related keywords |
| SE::Yahoo | Парсинг всех данных с поисковой выдачи Yahoo: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Youtube | Парсинг данных с поисковой выдачи Youtube: ссылки, название, описание, имя пользователя, ссылка на превью картинки, кол-во просмотров, длина видеоролика |
| SE::Ask | Парсер американской поисковой выдачи Google через Ask.com: ссылки, анкоры, сниппеты, Related keywords |
| SE::Rambler | Парсинг всех данных с поисковой выдачи Rambler: ссылки, анкоры, сниппеты |
| SE::Startpage | Парсинг всех данных с поисковой выдачи Startpage: ссылки, анкоры, сниппеты |